
OpenAI研究 语言模型可以解释语言模型中的神经元
语言模型的功能越来越强大,部署也越来越广泛,但我们对它们如何在内部工作的理解仍然非常有限。例如,可能很难从他们的输出中检测出他们是使用有偏见的启发式方法还是进行欺骗。可解释性研究旨在通过观察模型内部来发现更多信息。
可解释性研究的一个简单方法是首先了解单个组件(神经元和注意力头)在做什么。传统上,这需要人类手动检查神经元,以找出它们所代表的数据的特征。这个过程不能很好地扩展:很难将其应用于具有数百亿或数千亿参数的神经网络。我们提出了一个自动化过程,该过程使用GPT-4来生成和评分神经元行为的自然语言解释,并将其应用于另一种语言模型中的神经元。
这项工作是我们对齐研究方法的第三支柱的一部分:我们希望将对齐研究工作本身自动化。这种方法的一个有希望的方面是,它可以随着人工智能的发展速度而扩展。随着未来模型作为助手变得越来越智能和有用,我们将找到更好的解释。
如何处理?
这里的方法包括在每个神经元上运行3个步骤。
漫威漫画氛围
第 1 步:使用 GPT-4 生成解释
作为大银幕上的复仇者联盟,乔斯·惠登重返漫威,与漫威的超级英雄们重聚,迎接他们迄今为止最严峻的挑战。《复仇者联盟:奥创纪元》让有名无实的英雄们与有感知力的人工智能对抗,《聪明的金钱》表示,这部电影的票房可能会飙升,成为今年票房最高的电影 | 尽管漫威工作室老板凯文·费格告诉《娱乐周刊》,“托尼是地球人,面对的是地球上的恶棍。你不会发现魔法力量环发射冰和火焰束。”剧透!但他确实暗示它们有一些用处…STARK T |
这意味着这部《夜翼》电影可能不是关于那个曾经拥有那套西装的人。因此,除非新导演马特·里夫斯的《蝙蝠侠》将深入挖掘其中的一些背景故事,或者在他的电影中介绍迪克·格雷森这个角色,否则这部《夜翼》电影将有很多工作要做 | 没有出现在电影中的复仇者联盟和雷神试图与无限强大的魔法太空火鸟战斗。这最终毫无意义,是一个令人尴尬的损失,我敢肯定托尔意外地摧毁了一个星球。这是正确的。为了拯救地球,其中一位英雄不小心炸毁了一个 |
给定一个 GPT-2 神经元,通过显示相关的文本序列和对 GPT-4 的激活来生成其行为的解释。
模型生成的解释:
对电影、角色和娱乐的引用。第 2 步:使用 GPT-4 进行模拟
再次使用 GPT-4 模拟为解释而触发的神经元会做什么
:奥创纪元,听起来他的角色将在漫威电影宇宙中扮演比你们最初想象的更重要的角色。漫威发布了一份新的新闻稿,提供了关于电影中角色的一些信息。它包含的一切都是非常标准的东西,但后来有了这个新东西 | 他们即将为漫威的《夜魔侠》拍摄的13集连续剧。故事开始时,年轻的马特·默多克告诉他的盲人武术大师斯蒂克,他在9岁时失明了。然后我带着感激的凯伦·佩奇来到了现在,她解释说,一名蒙面治安维持者救了她的命。 |
| 另类的,截图|关注本文作者@KartikMdgl我们有两张来自Skyrim的图片,这让我们完全不知所措。它们显示了一个行走的桶,我们不确定这到底是怎么发生的。看看下面这两张图片。有些人真的会做一些奇怪的事情 | 极致轻便便携。该系列的四款型号XLS1000、XLS1500、XLS2000和XLS2500能够产生令人心跳加速的低音和清晰的高音,能够可靠且在预算内满足任何苛刻的音频要求。每一款XLS |
第 3 步:比较
根据模拟激活与实际激活的匹配程度对解释进行评分
模拟: | 实际: :奥创纪元,听起来他的角色将在漫威电影宇宙中扮演比你们最初想象的更重要的角色。漫威发布了一份新的新闻稿,提供了关于电影中角色的一些信息。它包含的一切都是非常标准的东西,但后来有了这个新东西 |
| 模拟: 他们即将为漫威的《夜魔侠》推出的13集系列。故事开始于一个年轻的马特·默多克告诉他的盲人武术大师斯蒂克,他在9岁时失明了。然后我带着感激的凯伦·佩奇来到了现在,她解释说,一名蒙面治安维持者救了她的命。 | 实际: 他们即将为漫威的《夜魔侠》推出的13集系列。故事开始于一个年轻的马特·默多克告诉他的盲人武术大师斯蒂克,他在9岁时失明了。然后我带着感激的凯伦·佩奇来到了现在,她解释说,一名蒙面治安维持者救了她的命。 |
| 模拟: 另类,截图|关注作者@KartikMdgl我们有两张来自Skyrim的照片,这让我们完全不知所措。它们显示了一个行走的桶,我们不确定这到底是怎么发生的。看看下面这两张图片。 有些人真的会做一些奇怪的事 | 实际: offbeat,截图|关注作者@KartikMdgl我们有两张来自Skyrim的图片,这让我们完全不知所措。它们显示了一个行走的桶,我们不确定这到底是怎么发生的。看看下面这两张图片。有些人真的会做一些奇怪的事 |
| 模拟: 极致轻便便携。该系列的四款车型XLS1000、XLS1500、XLS2000和XLS2500能够产生令人心跳加速的低音和清晰的高音,能够可靠且在预算范围内满足任何苛刻的音频要求。每XLS | 实际: 极致轻便便携。该系列的四款车型XLS1000、XLS1500、XLS2000和XLS2500能够产生令人心跳加速的低音和清晰的高音,能够可靠且在预算范围内满足任何苛刻的音频要求。每XLS |
我们的发现
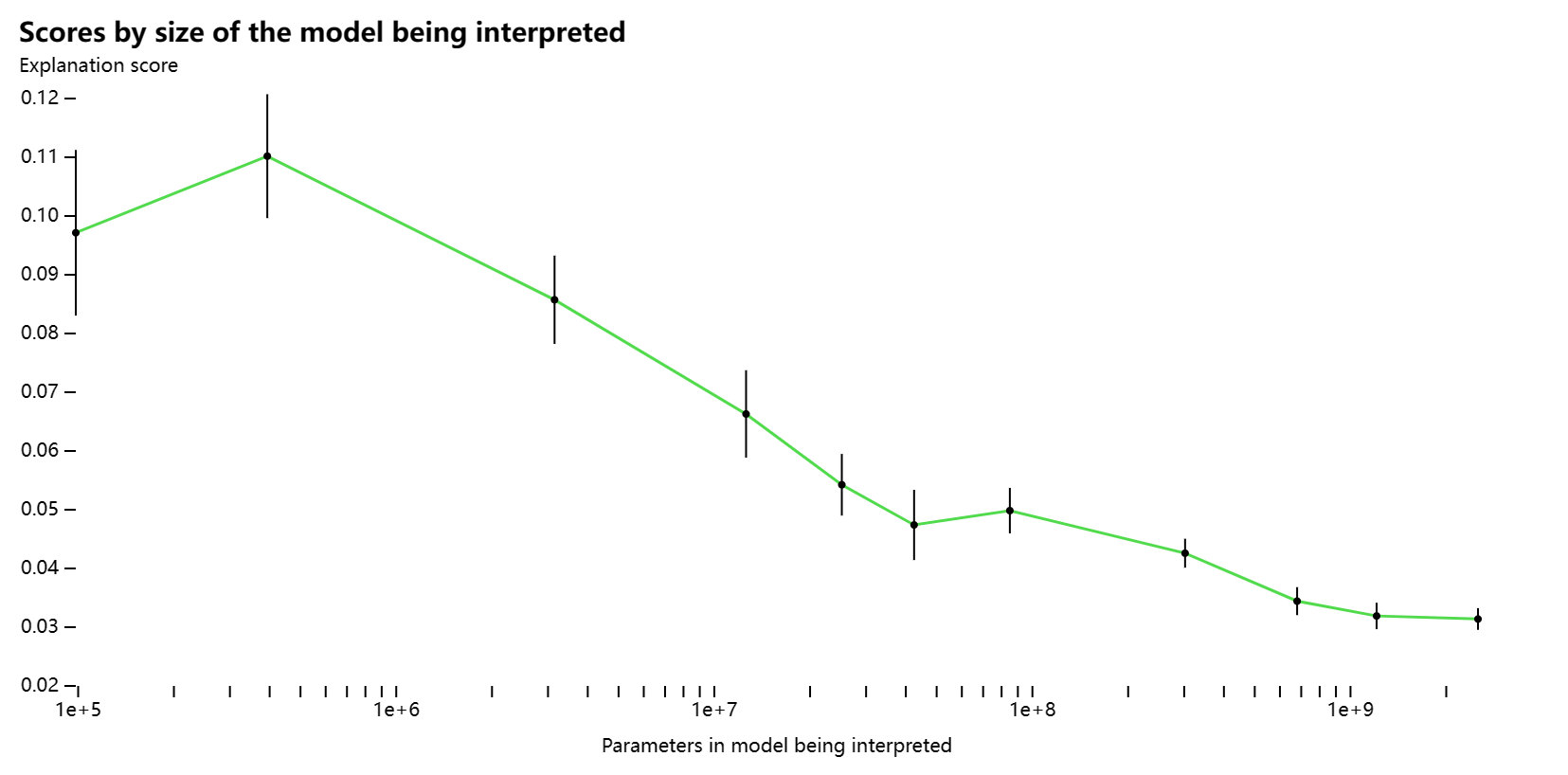
使用我们的评分方法,我们可以开始衡量我们的技术在网络的不同部分的效果如何,并尝试改进目前解释不佳的部分的技术。例如,我们的技术对较大的模型效果不佳,可能是因为后面的层更难解释。
尽管我们的绝大多数解释得分都很低,但我们相信我们现在可以使用ML技术来进一步提高我们产生解释的能力。例如,我们发现我们能够通过以下方式提高分数:
- 迭代解释。 我们可以通过要求 GPT-4 提出可能的反例,然后根据它们的激活修改解释来增加分数。
- 使用更大的模型给出解释。 随着解释器模型功能的提高,平均分数也会上升。然而,即使是 GPT-4 给出的解释也比人类更糟糕,这表明还有改进的空间。
- 更改所解释模型的体系结构。 具有不同激活函数的训练模型提高了解释分数。
我们正在开源我们的数据集和可视化工具,用于 GPT-4 中所有 307,200 个神经元的 GPT-2 编写解释,以及用于解释和评分的代码使用公开可用的模型在OpenAI API上。我们希望研究界能够开发新技术来生成更高分数的解释,以及更好的工具来使用解释来探索 GPT-2。
我们发现超过1个神经元的解释得分至少为000.0,这意味着根据GPT-8,它们占神经元顶级激活行为的大部分。这些解释清楚的神经元中的大多数都不是很有趣。然而,我们也发现了许多 GPT-4 不理解的有趣神经元。我们希望随着解释的改进,我们能够迅速发现对模型计算的有趣定性理解。
凯特
我们的许多读者可能都知道,日本消费者非常喜欢独特而富有创意的奇巧产品和口味。但是现在,雀巢日本公司推出了一种可以说不仅仅是一种新口味,而是Kit Kat的新“物种”。
令牌:凯特
展望
我们的方法目前有很多局限性,我们希望可以在今后的工作中解决这个问题。
- 我们专注于简短的自然语言解释,但神经元可能具有非常复杂的行为,无法简洁地描述。例如,神经元可以是高度多义的(代表许多不同的概念),或者可以代表人类不理解或没有单词的单个概念。
- 我们希望最终自动找到并解释整个神经回路实现复杂的行为,神经元和注意力头一起工作。我们目前的方法只将神经元行为解释为原始文本输入的函数,而没有说明其下游效应。例如,在句点上激活的神经元可能指示下一个单词应以大写字母开头,或者递增句子计数器。
- 我们解释了神经元的行为,但没有试图解释产生这种行为的机制。这意味着即使是高分解释在分发外的文本上也可能做得很差,因为它们只是在描述相关性。
- 我们的整个过程是相当计算密集型的。
我们对方法的扩展和推广感到兴奋。最终,我们希望使用模型来形成、测试和迭代完全一般的假设,就像可解释性研究人员一样。
最终,我们希望将最大的模型解释为在部署前后检测对齐和安全问题的一种方式。然而,在这些技术能够揭露不诚实等行为之前,我们还有很长的路要走。
相关文章
近期评论
-
来自: GPT-4V(ision)系统卡

-
来自: GPT-4V(ision)系统卡
-
来自: OpenAI研究 用对抗样本攻击机器学习