OpenAI研究 语言模型可以解释语言模型中的神经元论文
作者 史蒂文·比尔斯∗, 尼克·卡马拉塔∗, 丹·莫辛∗, 亨克·蒂尔曼∗, 高磊∗, 加布里埃尔·吴, 伊利亚·苏茨克弗, 扬·莱克, 吴杰夫∗, 威廉·桑德斯∗
* 核心研究贡献者; 作者 贡献声明如下。 与 interpretability@openai.com 的通信。 联系 开放人工智能 发表 9月 2023
介绍
语言模型已经变得更有能力,部署更广泛,但我们不了解它们是如何工作的。最近的工作在理解少量电路和狭窄行为方面取得了进展,但要完全理解语言模型,我们需要分析数百万个神经元。本文将自动化应用于将可解释性技术扩展到大型语言模型中的所有神经元的问题。我们希望,基于这种自动化可解释性的方法,使我们能够在部署之前全面审核模型的安全性。
我们的技术试图解释文本中的哪些模式导致神经元激活。它由三个步骤组成:
步骤 1 使用 GPT-4 解释神经元的激活
步骤 2 使用 GPT-4 模拟激活,以解释为条件
步骤 3通过比较模拟和真实激活来对解释进行评分
实际激活:
: 奥创纪元 听起来他的角色 将在 漫威电影宇宙中发挥比你们 最初一些人更大的作用想。 漫威有一份新的 新闻稿,提供了 一些关于电影中 角色的信息。 其中包含的所有内容都是非常标准的东西,但是后来有 这个新的
他们即将为漫威夜魔侠制作的 13 集系列。 故事开始于 年轻的马特·穆尔德·奥克告诉他的盲人武术大师斯蒂克,他在 9 岁时失明了——岁了。 然后我带着感激的 凯伦佩奇解释说,一个蒙面义警救了她的命。
不合时宜 , SC重拍 | 关注这位作者@KartikMdgl 我们有 两张来自天际的图像,完全 让我们感到震惊。 他们展示了一个行走的桶, 我们 不确定 这是怎么发生的。 看看下面的这两 张图片。 有些人 真的做了一些奇怪的事情
终极轻量级端口能力。 该 系列的四个型号—— X LS1000、X LS1500、X LS 2000 和 X LS 2500 – 专为满足任何苛刻的音频要求而设计 – 可靠且在预算范围内。 每 XLS
模拟激活:
: 奥创纪元 听起来他的角色 将在 漫威电影宇宙中发挥比你们 最初一些人更大的作用想。 漫威有一份新的 新闻稿,提供了 一些关于电影中 角色的信息。 其中包含的所有内容都是非常标准的东西,但是后来有 这个新的
他们即将为漫威夜魔侠制作的 13 集系列。 故事开始于 年轻的马特·穆尔德·奥克告诉他的盲人武术大师斯蒂克,他在 9 岁时失明了——岁了。 然后我带着感激的 凯伦佩奇解释说,一个蒙面义警救了她的命。
不合时宜 , SC重拍 | 关注这位作者@KartikMdgl 我们有 两张来自天际的图像,完全 让我们感到震惊。 他们展示了一个行走的桶, 我们 不确定 这是怎么发生的。 看看下面的这两 张图片。 有些人 真的做了一些奇怪的事情
终极轻量级端口能力。 该 系列的四个型号—— X LS1000、X LS1500、X LS 2000 和 X LS 2500 – 专为满足任何苛刻的音频要求而设计 – 可靠且在预算范围内。 每 XLS
比较模拟和真实激活以查看它们的匹配程度,我们得出一个分数:
0.337
选择一个神经元:
第 0 层神经元 816:与漫威漫画、电影和角色相关的语言,以及其他超级英雄主题内容
这种技术使我们能够利用GPT-4来定义和自动测量可解释性的定量概念,我们称之为“解释分数”:衡量语言模型使用自然语言压缩和重建神经元激活的能力。事实上,这个框架是定量的,这使我们能够衡量实现使神经网络的计算为人类所理解的目标的进展。
使用我们的基线方法,解释达到了接近人工承包商绩效水平的分数。我们发现,我们可以通过以下方式进一步提高性能:
· 迭代解释。我们要求 GPT-4 提出可能的反例,然后根据它们的激活情况修改解释。
· 使用更有能力的模型来给出解释。随着解释器模型能力的提高,平均分数会上升,GPT-4 获得最高分。
· 使用功能更强大的模型来模拟以解释为条件的激活。随着模拟器模型能力的提高,平均分数以及分数和人类比较之间的一致性都会上升,GPT-4 获得了最高分。
然而,我们发现基于 GPT-4 和人工承包商的解释在绝对值上得分仍然很低。在观察神经元时,我们还发现典型的神经元看起来非常多语义。这表明我们应该改变我们正在解释的内容。在初步实验中,我们尝试了:
· 更改所解释模型的体系结构。我们在使用不同激活函数训练的模型上获得了更高的解释分数。
· 寻找更多可解释的方向。我们对分数直接优化的初步研究表明,我们可以找到一些解释良好的神经元线性组合。
我们将我们的方法应用于GPT-2 XL中的所有MLP神经元。我们发现超过1个神经元的解释得分至少为000.0,这意味着根据GPT-8,它们占神经元顶级激活行为的大部分。我们使用这些解释来构建新的用户界面来理解模型,例如,允许我们快速查看哪些神经元在特定数据集示例中激活以及这些神经元的作用。
示例 1(共 4 个)
我们的许多读者可能都知道 ,日本消费者 非常喜欢 独特和 创意奇巧产品和 口味。 但是现在,Nest le Japan已经推出了 可以 说 不是的东西 只是一种新的 口味,但却是 Kit Kat的新“物种”。 为什么 我们称它 为新物种? 嗯,这是因为 你只需要 做 一点 点 烹饪以充分享受这些套件。
我们正在开源 GPT-2 XL 中所有神经元的解释数据集、解释和评分代码,以鼓励进一步研究,以产生更好的解释。我们还使用数据集发布了一个神经元查看器。虽然大多数解释清楚的神经元都不是很有趣,但我们发现了许多 GPT-4 不理解的有趣神经元。我们希望这能让其他人更容易地在我们的工作之上进行构建。随着未来更好的解释和工具,我们也许能够快速发现对模型计算的有趣定性理解。
方法
设置
我们的方法涉及多种语言模型:
· 主题模型是我们试图解释的模型。
· 解释器模型提出了有关主体模型行为的假设。 1
· 模拟器模型根据假设进行预测。根据预测与现实的匹配程度,我们可以判断假设的质量。模拟器模型应该像理想化的人一样解释假设。 2
在本文中,我们从最简单的情况开始,即识别与中间激活相关的文本输入的属性。我们最终希望扩展我们的方法,以探索有关主题模型计算的任意假设。
在语言模型的情况下,输入是文本段落。对于中间激活,我们专注于MLP层中的神经元。对于本文的其余部分,激活是指 MLP 激活后值,计算公式为哪里ff是一个非线性激活函数(特别是 GPT-2 的 GELU)。然后使用神经元激活通过添加来更新残余流
当我们对神经元有一个假设的解释时,假设是神经元激活具有该属性的令牌,其中属性可能包含以前的令牌作为上下文。
整体算法
在高层次上,我们解释神经元的过程使用以下算法:
· 解释:通过显示神经元对文本摘录的响应中的解释器模型(令牌、激活)对来生成神经元行为的解释
· 模拟:使用模拟器模型根据解释模拟神经元的激活
· 分数:根据模拟激活与实际激活的匹配程度自动对说明进行评分
我们始终使用不同的文档来生成和模拟解释。 3
我们用于生成解释、模拟神经元和评分解释的代码可在此处获得。
第 1 步:生成神经元行为的解释
在此步骤中,我们创建一个发送到解释器模型的提示,以生成神经元行为的一个或多个解释。该提示由其他真实神经元的几个镜头示例组成,带有来自文本摘录和研究人员编写的解释的制表符分隔(标记,激活)对。最后,少数镜头示例包含制表符分隔(标记、激活)对,这些对来自正在解释的神经元的文本摘录。 4
激活被规范化为0-10尺度,并离散化为整数值,负激活值映射到0,神经元观察到的最大激活值映射到10。对于神经元激活稀疏(<20%非零)的序列,我们发现在完整的令牌列表之后额外重复具有非零激活的令牌/激活对很有帮助,帮助模型专注于相关令牌。
第 2 步:使用解释模拟神经元的行为
通过这种方法,我们旨在回答这个问题:假设一个提议的解释准确而全面地解释了神经元的行为,那么该神经元将如何激活特定序列中的每个标记?为此,我们使用模拟器模型来模拟每个主题模型令牌的神经元激活,条件是提出的解释。
我们提示模拟器模型为每个主题模型令牌输出一个介于 0-10 之间的整数。对于每个预测的激活位置,我们检查分配给每个数字(“0”,“1”,“...”,“10”)的概率,并使用这些概率来计算输出的期望值。因此,得到的模拟神经元值是[0, 10]尺度上的。
我们最简单的方法是我们所说的“一次一个”方法。该提示由一些少数样本示例和预测单个令牌激活的单镜头示例组成。
不幸的是,“一次一个”方法非常慢,因为它需要每个模拟令牌进行一次正向传递。我们使用一个技巧来并行化所有令牌的概率预测,方法是使用几个样本,其中激活值从“未知”切换到序列中随机位置的实际值。通过这种方式,我们可以在上下文中模拟具有“未知”的神经元,同时仍然通过检查“未知”标记的对数来引发模型预测,并且模型从未观察到相关神经元的任何实际激活值。我们称之为“一次全部”方法。
由于速度优势,我们对论文的其余部分使用“一次全部”评分,除了一些小规模的定性结果。 5 除了速度更快之外,我们令人惊讶地发现,使用“一次全部”方法计算的分数在预测解释之间的人类偏好方面与“一次一个”方法一样准确。“一次一个”实际上优于“一次一个”, 6
第 3 步:通过比较模拟和实际神经元行为来对解释进行评分
从概念上讲,给定一个解释和模拟策略,我们现在有一个模拟神经元,一个“神经元”,我们可以预测任何给定文本摘录的激活值。为了对解释进行评分,我们希望将这个模拟神经元与生成解释的真实神经元进行比较。也就是说,我们要比较两个值列表:多个文本摘录解释的模拟激活值,以及同一文本摘录上真实神经元的实际激活值。
从概念上讲,一个简单的方法是在所有令牌中使用模拟激活的真实激活的解释方差。也就是说,我们可以计算哪里指示给定解释的模拟激活,以及指示真正的激活,并且期望跨所选文本摘录中的所有令牌。 7
但是,我们的模拟激活是 [0, 10] 比例的,而实际激活将具有一些任意分布。因此,我们假设能够将模拟神经元的激活分布校准为实际神经元的分布。我们选择简单地线性校准 8 在评分的文本摘录上获得成本很高。 9 如果是真实激活和模拟激活之间的相关系数,然后我们缩放模拟,使其平均值与真实激活的平均值匹配,并且它们的标准差为乘以真实激活的标准偏差。这在以下位置最大化解释的方差�2ρ2 10 .
这激发了我们的主要评分方法,相关性评分,它只是报告.请注意,如果模拟神经元的行为与真实神经元相同,则分数为 1。如果模拟神经元的行为是随机的,例如,如果解释与神经元行为无关,则分数将趋于0左右。
针对消融评分进行验证
理解网络的另一种方法是在前向传递期间扰动其内部值并观察效果。这提出了一种更昂贵的评分方法,我们用模拟神经元替换真实的神经元(即将其激活消融到模拟的激活值)并检查网络行为是否保留。
为了衡量从消融到模拟的行为变化程度,我们使用扰动模型和原始模型的输出对数之间的 Jensen-Shannon 散度,在所有令牌上取平均值。作为比较的基线,我们执行第二次扰动,将神经元的激活消融到所有令牌的平均值。对于每个神经元,我们通过消融到平均值的背离来规范化消融到模拟的发散。因此,我们将消融评分表示为哪里指示对文本摘录运行模型�x随着神经元消融并返回每个标记处的预测分布,平均JSD平均JSD取每个代币的詹森-香农背离并取平均值,是序列上模拟神经元值的线性校准向量,并且是该神经元在所有令牌中的平均激活。请注意,对于此消融评分,与相关评分一样,机会表现得分为 0.0,完美表现得分为 1.0。
仅随机评分顶部和随机评分

我们发现,平均而言,相关性评分和消融评分之间有着明确的关系。因此,本文的其余部分使用相关性评分,因为它的计算要简单得多。然而,相关性评分似乎并没有捕捉到消融评分所揭示的模拟解释中的所有缺陷。特别是,0.9的相关分数仍然导致平均消融分数相对较低(仅随机文本摘录的分数为0.3,顶部和随机的分数为0.6;关于如何选择这些文本摘录,见下文)。11
根据人工评分进行验证
一个潜在的担忧是,基于模拟的评分实际上并不能反映人类对解释的评估(更多讨论请参阅此处)。我们收集了人类对解释质量的评估,看看他们是否同意基于分数的评估。
我们给人类标注者任务,让他们看到与模拟器模型相同的文本摘录和激活(用颜色高亮显示)(包括顶部激活和随机),并要求他们根据这些解释对激活模式的捕捉程度对5种提出的解释进行评级和排序。我们发现解释者模型的解释并不多样,因此通过改变解释生成提示中使用的少数镜头示例,或通过使用修改后的提示,要求解释者模型在一次完成中提供可能解释的编号列表,增加了解释的多样性。
我们的研究结果表明,人类倾向于喜欢高分解释而不是低分解释,随着分数差距的大小增加,这种偏好的一致性也在增加。
算法参数和详细信息
在整个工作中,除非另有说明,否则我们使用 GPT-2 预训练模型作为主题模型,使用 GPT-4 作为解释器和模拟器模型。 12
对于生成和模拟解释,我们从主题模型的预训练数据集的训练拆分中获取文本摘录(例如,对于 GPT-2 模型的 WebText)。我们选择文档的随机 64 标记连续子序列作为我们的文本摘录。 13 格式与模型的训练方式相同,只是我们从不跨越文档边界。 14
在生成解释时,我们使用 5 个“顶级激活”文本摘录,其中至少有一个具有极大激活值的标记,由最大激活的分位数确定。这是因为我们凭经验发现:
· 在解释生成提示中专门使用顶部激活序列会产生最佳的解释分数,即使仅针对随机序列或针对具有较低分位数激活的序列进行评分(见下图)。事实上,我们发现,从 1,20 个文本摘录中的前 000 名上升到 1,60 个文本摘录中的前 000 名,也取得了明显的增长。
· 当使用 16-64 个标记文本摘录时,即使用于评分的序列更长,解释分数也最高。
· 使用超过 5-10 个文本摘录来生成解释不会显着影响分数(尽管与序列长度存在一些交互作用)。
· 在解释生成中包括随机或低分位数序列的示例会提示降低解释分数。
· 解释最大负激活序列也给出了极低的解释分数。 15

因此,对于本文的其余部分,除非另有说明,否则总是从5个顶部激活序列生成解释。我们设定了0.9996的最高分位数阈值,从50000个总序列中选取了含有最高激活的20个序列。我们在温度1下对解释进行采样。
为了进行模拟和评分,我们报告了5个统一随机的文本摘录(“仅随机”)。仅随机得分可以被认为是一种解释,它能够捕捉神经元对预训练分布中特征的表示。虽然仅随机评分在概念上很容易理解,但我们也报告了5个顶部激活和5个随机文本摘录(“顶部和随机”)的混合评分。顶部和随机得分可以被认为是一种解释,它能够捕捉神经元最强烈的表征特征(来自顶部文本摘录),并对过于宽泛的解释(来自随机文本摘录)进行惩罚。与仅随机得分相比,得分最高且随机得分有几个实用优势:
•随机文本摘录会导致显著更高的方差得分。根据经验,我们发现只在随机评分中表现良好的神经元是密集的激活神经元。大多数神经元都很稀疏,虽然大量神经元的平均值可能是有信息的,但单个神经元的得分通常是没有信息的。
•考虑到多义性,神经元可能需要超长/析取的解释。即使是与一个特征相对应的神经元也可能受到其他特征的实质性干扰。只解释极端情况下的行为似乎是获得更干净功能的合理方法,从长远来看,这可能更类似于我们希望解释的内容。
·
我们希望能够对敌对选择的文本摘录进行评分,例如对我们的解释进行修订。在保持制服而不是训练前口译的同时,这样做更具挑战性。16此外,1的完美相关性(或解释的方差)仍然具有类似的解释。
请注意,小样本量的“仅随机”评分有可能无法捕捉行为,因为缺乏高模拟激活度的代币和高真实激活度的令牌。“顶部和随机”评分解决了后者,但导致我们对虚低模拟的惩罚多于对虚高模拟的惩罚,因此倾向于接受过于宽泛的解释。一种更原则的两全其美的方法可能是坚持只随机评分,但增加只随机的文本摘录的数量,并结合使用重要性抽样作为方差减少策略。17
下面我们展示了一些神经元评分的典型例子。
上一个
下一个
由于在低激活状态下的行为,具有特别好的顶部和随机得分,但仅随机得分较差的神经元
后果
解释注意事项:在本节中,我们的结果可能使用略有不同的方法(例如,不同的解释者模型、不同的提示等)获得。因此,不同图表之间的分数并不总是可比较的。在所有绘图中,误差条对应于平均值的95%置信区间。18
总的来说,对于GPT-2,我们发现使用顶部和随机评分的平均得分为0.151,仅使用随机评分的得分为0.037。进入后期图层时,分数通常会降低。
第0层
仅随机得分Top和随机得分

注意,神经元的个体评分可能是有噪声的,尤其是对于仅随机评分。考虑到这一点,使用我们的默认方法,在307200个神经元中,5203个(1.7%)的最高和随机得分超过0.7(解释了大约一半的方差)。在仅随机评分的情况下,这一数字降至732个神经元(0.2%)。只有189个神经元(0.06%)的最高和随机评分超过0.9,86个神经元(0.03%)的仅随机评分高于0.9。
Unigram基线
为了从绝对角度理解我们解释的质量,与不依赖于语言模型总结或模拟激活能力的基线进行比较是有帮助的。出于这个原因,我们研究了几种基于单个令牌直接预测激活的基线方法,使用模型权重或保存文本中聚合的激活数据。对于每个神经元,这些方法为词汇表中的每个标记提供一个预测的激活值,这相当于比语言模型产生的简短自然语言解释多得多的信息。出于这个原因,我们还使用语言模型简要总结了这些激活值列表,并在我们的典型模拟管道中对此进行了解释。
单击以显示缩写的令牌解释提示
使用权重进行基于令牌的预测
logit透镜和相关技术将神经元权重与令牌相关联,试图根据导致神经元激活的令牌或神经元导致模型采样的令牌来解释神经元。从根本上说,这些技术取决于神经元的输入或输出权重乘以嵌入矩阵或未嵌入矩阵。
为了线性预测每个令牌的激活,我们将每个令牌嵌入乘以MLP前层范数增益和神经元输入权重。这种方法允许为词汇表中的每个令牌分配一个标量值。使用此方法预测的激活仅取决于当前令牌,而不取决于先前的上下文。这些标量值直接用于预测每个令牌的激活,而不进行汇总。这些基于权重的线性预测是机械或“因果”解释,因为权重直接影响神经元的输入模式,从而影响其激活模式。
基于线性标记的预测基线优于第一层的基于激活的解释和评分,几乎完美地预测了激活(考虑到只有第一注意力层介入嵌入和第一MLP层之间,这并不令人惊讶)。对于所有后续层,基于GPT-4的解释和评分比基于线性令牌的预测基线更好地预测激活。19
基于线性标记的预测基线在某种程度上是不公平的比较,因为词汇表中每个标记一个标量值的“解释长度”比基于GPT的自然语言解释长得多。使用语言模型将这些信息压缩成一个简短的解释并模拟该解释可能会成为影响预测激活准确性的“信息瓶颈”。为了控制这一点,我们尝试了一种混合方法,将基于GPT-4的解释应用于具有最高线性预测激活(对应于前100个值中的50个)的令牌列表,而不是应用于最高激活。这些解释比基于线性标记的预测或基于激活的解释得分更差。
仅随机得分Top和随机得分

使用查找表进行基于令牌的预测
基于令牌的线性预测基线可能由于以下几个原因之一而表现不如基于激活的基线。首先,它可能会失败,因为多标记上下文很重要(例如,许多神经元对多个标记短语很敏感)。其次,它可能会失败,因为在令牌嵌入和���胜利很重要,而线性预测很难代表令牌对神经元活动的真正因果影响。
为了评估第二种可能性,我们构建了第二个“相关”基线。对于这个基线,我们计算了在一个庞大的网络文本语料库中每个令牌和每个神经元的平均激活。然后,我们使用这些信息来构建一个查找表。对于文本摘录中的每个令牌和每个神经元,我们使用令牌查找表来预测神经元的激活,与前面的令牌无关。同样,我们不总结这个查找表的内容,也不使用语言模型来模拟激活。
令牌查找表基线比基于令牌的线性预测基线强得多,平均而言显著优于基于激活的解释和模拟。我们应用与基于令牌的线性基线相同的解释技术来测量使用GPT-4进行解释和模拟的信息瓶颈如何影响预测激活的准确性。
由此产生的基于令牌查找表的解释在顶部和随机评分上的得分与我们基于激活的解释相似,但在仅随机评分上优于基于激活的说明。然而,我们最感兴趣的是编码多令牌上下文而不是单个令牌的复杂模式的神经元。尽管平均性能较差,但我们发现许多有趣的神经元,其中基于激活的解释比基于令牌查找表的解释具有优势。我们还能够通过修改解释来改进基于令牌查找表的解释。从长远来看,我们计划使用结合基于令牌和基于激活的信息的方法。
仅随机得分Top和随机得分
下一个基于令牌的解释
我们注意到,一些神经元似乎编码预测的下一个令牌,而不是当前令牌,特别是在后面的层中(参见下面描述的“from”-预测神经元)。我们的基线方法用(前面的令牌,激活)对提示GPT-4,但无法捕捉这种行为。作为一种替代方案,我们提示GPT-4通过使用(下一个令牌,激活)对来解释和模拟神经元基于其最高激活之后的令牌的激活。这种方法对神经元子集更为成功,尤其是在后面的层中,并且在最后几层中平均获得了与基线方法相似的分数。
仅随机得分Top和随机得分
修改解释
解释质量从根本上受到单个解释提示中显示的一小部分文本摘录和激活的限制,这并不总是足以解释神经元的行为。重复解释可能会让我们有效地利用更多的信息,依靠大型语言模型在测试时使用推理来提高反应的突发能力。20
我们发现的一个特殊问题是,过于宽泛的解释往往与顶部激活序列一致。例如,我们发现了一个“并非所有”神经元,它会在短语“并非全部”和一些相关短语上激活。然而,选择用于解释的顶部激活文本摘录并没有推翻一个更简单的假设,即神经元在短语“all”上激活。因此,该模型产生了一个过于宽泛的解释:“所有”一词以及相关的上下文短语。21然而,观察不同上下文中包含“all”的文本摘录的激活,可以发现神经元实际上是在为“all”激活,但只有当短语“not all”的一部分时。从这个例子和其他类似的例子中,我们得出结论,在顶部和随机激活序列之外寻找新的证据将有助于更全面地解释一些神经元。
更糟糕的是,我们发现我们的解释技术往往没有考虑到负面证据(即神经元不放电的例子,这使某些假设不合格)。对于“并非所有”神经元,即使我们手动将负面证据添加到解释者上下文中(即包含零激活的“所有”一词的序列),解释者也会忽略这些,并产生同样过于宽泛的解释。解释者模型可能无法在单个正向传递中关注提示的所有方面。
为了解决这些问题,我们采用了两步修订流程。
第一步是寻找新的证据。我们使用GPT-4的几个镜头提示来生成10个与现有解释相匹配的句子。例如,对于“并非全部”神经元,GPT-4生成在非否定上下文中使用“全部”一词的句子。
点击显示句子生成提示
希望能为原始解释找到假阳性,即包含标记的句子,其中神经元的真实激活较低,但模拟激活较高。然而,我们不会针对这种情况过滤生成的句子。在实践中,大约42%的生成序列会导致它们的解释出现假阳性。对于86%的神经元,10个序列中至少有一个导致假阳性。这提供了一个独立的信号,表明我们的解释往往过于包容。我们将生成的10个句子分成两组:5个用于复习,5个用于评分。一旦我们生成了新的句子,我们就使用主题模型进行推理,并记录目标神经元的激活。
第二步是使用GPT-4的几个镜头提示来修改原始模型解释。提示包括用于生成原始解释、原始解释、新生成的句子以及这些句子的基本事实激活的证据。一旦我们获得了一个修订的解释,我们就在用于对原始解释进行评分的同一组序列上对其进行评分。我们还在同一集合上对原始解释和修订解释进行评分,并增加了新证据的评分。
单击以显示解释修订提示的缩写版本
我们发现,在原始评分集和扩充评分集上,修正后的解释都比原始解释得分高。正如预期的那样,原始解释在增强评分集上的得分明显低于原始评分集。
顶部和随机评分顶部和随机生成评分

我们发现修正很重要:用新句子重新解释(“重新解释”)但不使用旧的解释的基线不会比基线有所改善。作为后续实验,我们尝试使用具有非零激活的句子的小随机样本进行复习(“revision_rand”)。我们发现,这种策略提高解释分数的程度几乎与使用生成句子进行复习的程度相同。我们假设这在一定程度上是因为随机句子也是初始解释的假阳性来源:大约13%的随机句子包含原始模型解释的假阴性激活。
总的来说,修订让我们超过了代币查找表解释中的最高和随机得分,而不是仅随机得分,因此改进是有限的。22
仅随机得分Top和随机得分
定性地说,我们观察到的主要模式是,原始解释过于宽泛,修订后的解释过于狭隘,但修订后的说明更接近事实。例如,对于第0层神经元4613,最初的解释是“与基数和序数有关的单词”。GPT-4基于这一解释生成了10个句子,其中包括许多与这一描述相匹配的单词,这些单词最终缺乏显著的激活,如“第三”、“向东”、“西南”。修正后的解释是“这个神经元在引用序数‘第四’时激活”,这会产生更少的假阳性。尽管如此,修订后的解释并没有完全捕捉到神经元的行为,因为除了第四个词,还有几个词被激活,比如“荷兰”和“白色”。
我们还观察到,针对原始解释技术的问题进行的修订带来了一些有希望的改进。例如,一种常见的神经元激活模式是为一个单词激活,但仅在非常特定的上下文中激活。这方面的一个例子是“假设的had”神经元,它为“had”一词激活,但仅在假设或可能发生不同情况的情况下激活(例如,“如果我有能力这样做,我会永远关闭它。”。“然而,当被提供含有假阳性激活的句子时(例如,“他昨晚和朋友吃了晚饭”),审校者能够理解真实的模式并做出正确的解释。原始解释未能捕捉到但修订解释解释解释的其他一些神经元激活模式是“单词‘在一起’,但只有在前面加上单词“get”(例如“gettogether”、“gettorther”)和“单词“因为”,但仅当“仅仅因为”语法结构的一部分时”(例如,“仅仅因为某件事看起来是真实的,并不意味着它是真实的”)。
未来,我们计划探索不同的技术来改进证据来源和修订,如来源假阴性、应用思维链方法和微调。
寻找可解释的方向
神经元在自然语言中可以被简洁地解释的程度也限制了解释质量。我们发现,我们检测到的许多神经元都是多义的,这可能是由于叠加造成的。这提出了一种不同的方法,通过改进我们正在解释的内容来改进解释。我们探索了一种利用这种直觉的简单算法,使用我们的自动化方法来确定叠加的可能攻击角度。
高级思想是优化神经元的线性组合。23给定激活向量�a和单位向量�θ(方向),我们定义了一个具有激活的虚拟神经元��=��Σ−1/2�aθ=aT∑−1/2θ,其中∑∑是�a.24
从均匀随机方向开始�θ、 然后,我们使用坐标上升进行优化,交替执行以下步骤:
1.解释步骤:通过搜索解释来优化过度解释��θ良好(即获得高解释者分数)。
2.更新步骤:优化�θ,并执行梯度上升。请注意,我们的相关分数在�θ、 只要解释和模拟值是固定的。
对于解释步骤,最简单的基线是简单地使用典型的基于顶部激活的解释方法(其中每个步骤的激活都是针对虚拟神经元的)。然而,为了提高解释步骤的质量,我们使用具有生成的否定的修订,并重用以前步骤中的高分解释。
我们在GPT-2 small的第10层(倒数第二个MLP层)上运行了这个算法,该层有3072个神经元。对于每个3072维的方向,我们进行了10轮坐标上升。对于梯度上升,我们使用学习率为1e-2的Adam,�0.9的1β1,以及�2β2的比值为0.999。我们还重新缩放�θ是每次迭代的单位范数。
我们发现,10次迭代后的平均顶部和随机得分为0.718,大大高于该层中随机神经元的平均得分(0.147),并高于任何优化前随机方向的平均得分。
这个过程的一个潜在问题是,我们可能会重复地收敛在同一个可解释的方向上,而不是找到一组不同的局部最大值。为了检查这种情况发生的程度,我们测量并发现结果方向之间的余弦相似性非常低。
我们还检查了对∑−1/2贡献最大的神经元�∑−1/2θ,并定性地观察到它们通常在语义上完全无关,这表明所发现的方向不仅仅是特定的神经元或语义相似神经元的小组合。如果我们只截断到顶部�通过其激活与方向的激活的相关性,我们发现需要大量的神经元来恢复分数(解释固定)。25


方向
今天早上乌云密布。当天晚些时候云层有所减少。可能会有零星阵雨或雷暴。85华氏度附近的高温。SSE风,时速5至10英里。。今晚部分多云。可能会有零星阵雨或雷暴。低71
零星阵雨和雷暴。几场风暴可能会很严重。高78华氏度。SSW风,时速5至10英里。下雨的可能性为50%。。今晚可能会有雷暴。然后可能会在一夜之间出现分散的雷暴。几场风暴可能会很严重。低59
,IA(52732)今天下雨早。。。下午多云有阵雨。可能会打雷。高66华氏度。风轻且多变。下雨的可能性为80%。。今晚可能会有雷暴。温度低至60华氏度左右。SSE风速为5至10英里/小时
,好的(74078)今天多云,预计晚些时候会有阳光。高79华氏度。SSE风,时速5至10英里。。今晚今晚可能会有一两场阵雨,夜间多云。低57华氏度。风速为5至10英里/小时的E风
(17801)今天早上的云层和阳光混合在一起,今天下午的天空将多云。下阵雨的可能性很小。65华氏度附近的高温。风轻且多变。。今晚下雨。低56华氏度。风轻且多变。下雨的可能性100
最相关神经元
今天早上乌云密布。当天晚些时候云层有所减少。可能会有零星阵雨或雷暴。85华氏度附近的高温。SSE风,时速5至10英里。。今晚部分多云。可能会有零星阵雨或雷暴。低71
零星阵雨和雷暴。几场风暴可能会很严重。高78华氏度。SSW风,时速5至10英里。下雨的可能性为50%。。今晚可能会有雷暴。然后可能会在一夜之间出现分散的雷暴。几场风暴可能会很严重。低59
,IA(52732)今天下雨早。。。下午多云有阵雨。可能会打雷。高66华氏度。风轻且多变。下雨的可能性为80%。。今晚可能会有雷暴。温度低至60华氏度左右。SSE风速为5至10英里/小时
,好的(74078)今天多云,预计晚些时候会有阳光。高79华氏度。SSE风,时速5至10英里。。今晚今晚可能会有一两场阵雨,夜间多云。低57华氏度。风速为5至10英里/小时的E风
(17801)今天早上的云层和阳光混合在一起,今天下午的天空将多云。下阵雨的可能性很小。65华氏度附近的高温。风轻且多变。。今晚下雨。低56华氏度。风轻且多变。下雨的可能性100
这种方法的一个主要限制是,在优化可解释性的学习代理时必须小心。在我们能够对模型中的方向做出忠实的人类可以理解的解释的程度上,也可能存在理论上的局限性。
辅助模型趋势
解释模型扩展趋势
一个重要的希望是,随着我们的援助越来越好,解释会有所改进。在这里,我们使用不同的解释器模型进行实验,同时将模拟器模型固定在GPT-4。我们发现,使用解释器模型功能可以顺利地改进解释,并且在各个层之间可以相对均匀地改进。
仅随机得分Top和随机得分
我们还从被要求从头开始写解释的标注者那里获得了人类基线,使用了与解释者模型使用的相同的5个顶部激活文本摘录。我们的标注者是非专家,他们收到了指示和一些研究人员写的例子,但没有接受过关于神经网络或相关主题的更深层次的培训。
我们看到,人类的性能超过了GPT-4的性能,但差距不大。人的表现在绝对值上也很低,这表明改进解释的主要障碍可能不仅仅是解释者模型的能力。
模拟器模型缩放趋势
对于一个糟糕的模拟器,即使是一个很好的解释也会得到很低的分数。为了了解模拟器的质量,我们将解释分数视为模拟器模型能力的函数。我们发现顶部和随机得分的回报率很高,而仅随机得分的得分则趋于平稳。
仅随机得分Top和随机得分
当然,模拟质量不能用分数来衡量。然而,我们也可以使用前面描述的人类比较数据来验证来自更大模拟器的分数诱导的比较更符合人类。在这里,人类的基线来自人类的一致性比率。使用GPT-4作为模拟模型的分数正在接近,但仍略低于人类与其他人类的一致率。
主题模型趋势
我们的方法可以快速洞察主题模型的哪些方面会增加或减少解释得分。请注意,这些趋势的某些部分可能反映了我们特定解释方法的优势和劣势,而不是受试者模型神经元“可解释”的程度,或者人类只需适度努力就能理解的程度。如果我们的解释方法得到了足够的改进,这种方法可以深入了解模型的哪些方面增加或降低了可解释性。
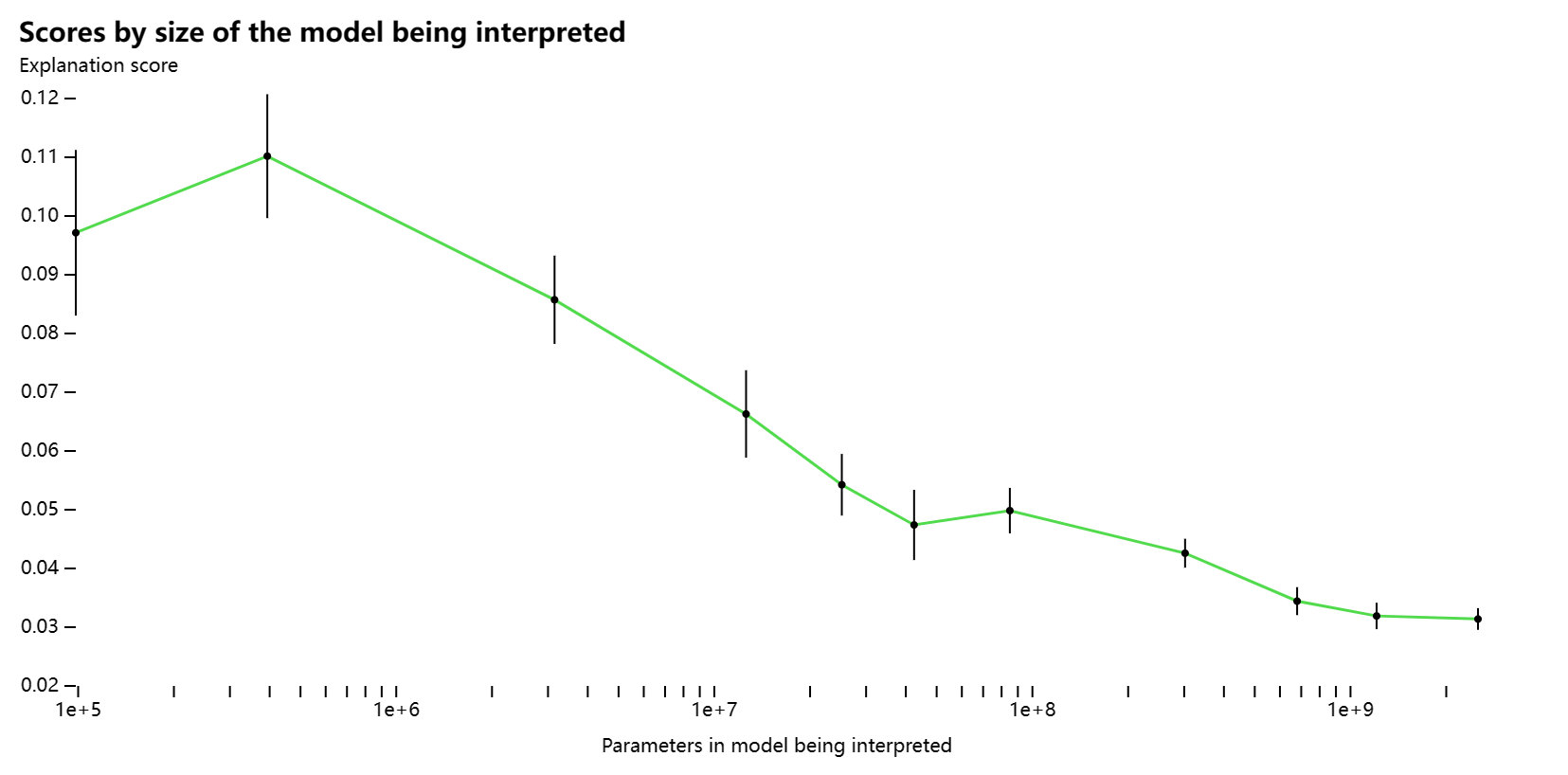
受试者模型尺寸
一个自然的问题是,更大、更强大的模型是否比更小的模型更难理解。因此,我们测量了GPT-3系列中受试者模型的解释分数,其大小从98K到6.7B不等。一般来说,使用我们的方法,随着模型大小的增加,我们看到神经元的可解释性呈下降趋势,仅随机评分的趋势尤其明显。
仅随机得分Top和随机得分
为了理解这种趋势的基础,我们按层检查可解释性。对于第 16 层以后,平均解释分数随着深度的增加而大幅下降,使用顶部和随机评分以及仅随机评分。对于较浅的层,顶部和随机分数也随着深度的增加而降低, 26 。 而仅随机分数主要随着模型大小的增加而降低。由于模型越大,层数越多,这些趋势共同意味着解释分数会随着模型大小的增加而下降。
仅随机评分顶部和随机评分

请注意,这些趋势可能是人为的,因为它们主要反映了我们当前解释生成技术的局限性。我们对基于“下一个令牌”的解释的实验证实了这样的假设,即较大模型的后期层具有神经元,其行为是可以理解的,但对于我们目前的方法来说很难解释。
主体模型激活功能
一个有趣的问题是模型的架构是否会影响其可解释性,尤其是在模型的稀疏性方面。为了研究这一点,我们使用稀疏激活函数从头开始训练一些小型(~3M 参数)模型,该函数应用标准激活函数,但随后仅在每层中保留固定数量的顶级激活,其余部分设置为零。我们尝试不同水平的激活密度:1(基线),0.1,0.01和0.001(前2个神经元)。我们希望激活稀疏性应该阻止极端的多义性。
仅随机评分顶部和随机评分

增加激活稀疏性会持续增加解释分数,但会损害训练前的损失。 27 我们还发现,RELU始终比GeLU产生更好的解释分数。
主体模型训练时间
另一个问题是训练时间如何影响固定模型架构的解释分数。为了研究这一点,我们查看 GPT-3 系列中模型中间检查点的解释分数,对应于训练的一半和四分之一。 28
仅随机评分顶部和随机评分

更多训练往往会提高顶部和随机分数,但会降低仅随机分数。 29 在损失性能的固定水平下,较小的模型可能具有更高的解释分数。
我们还发现,在同一训练运行的不同检查点之间,解释存在显著的正向转移。例如,当使用完全训练模型的解释时,四分之一训练模型的分数似乎下降不到 25%,反之亦然。这表明特征-神经元对应关系的稳定性相对较高。
定性结果
有趣的神经元
在整个项目中,我们发现了许多有趣的神经元。GPT-4 能够找到我们认为合理的非平凡神经元的解释,例如“明喻”神经元、与确定性和信心相关的短语的神经元,以及正确完成事情的神经元。
寻找有趣神经元的一个成功策略是寻找那些与基于激活的解释相比,它们的令牌空间解释解释不佳的神经元。这导致我们同时发现在某些上下文中密集激活的上下文神经元 30 。 以及许多神经元在文档开头激活的特定单词。
另一个不依赖于解释质量的相关策略是寻找上下文敏感的神经元,当上下文被截断时,这些神经元的激活方式不同。这导致我们发现了一个模式中断神经元,它激活在正在进行的列表中打破既定模式的标记(下面在某些选择句子中显示)和一个后错别字神经元,它经常在奇怪或截断的单词之后激活。我们的解释模型通常无法在有趣的上下文相关神经元上得到正确的解释。

我们注意到许多神经元似乎在与特定的下一个标记匹配的情况下激活,例如激活下一个标记可能是单词“from”的神经元。最初,我们假设这些神经元可能会根据其他信号预测下一个令牌。然而,其中一些神经元的消融与这个故事不符。“from”神经元似乎实际上略微降低了“from”输出的可能性。同时,它增加了“形式”一词变体的可能性,这表明它正在做的事情之一是考虑错别字的可能性。由于它处于后期层(44 个中的 48 个),这个神经元可能正在响应网络已经将高概率放在单词“from”上的情况。我们还没有进行足够的研究,无法清楚地了解正在发生的事情,但是许多神经元可能根据特定输入对输出分布进行编码,而不是执行其激活所暗示的明显功能。
我们发现了一些有趣的神经元对特定类型的重复做出反应的例子。我们发现了一个神经元,它可以激活重复出现的令牌,根据出现的次数,激活更强。多语义神经元的一个有趣例子是,一个神经元同时触发短语“一遍又一遍”和“在一个不重复的数字之前重复的事情”,可能是因为“一遍又一遍”本身包括重复。我们还发现了两个神经元,当与不同的名字结合时,它们似乎主要对第二次提及姓氏做出反应。这些神经元可能对感应头做出反应。
[42]
总的来说,我们的主观感觉是,更有能力的模型的神经元往往更有趣,尽管我们花了大部分精力研究GPT-2 XL神经元而不是更现代的模型。
有关更多有趣的神经元,请参阅我们的神经元可视化网站。
解释构建的谜题
在思考如何定性地理解我们的解释方法时,我们经常遇到两个问题。首先,我们对解释或分数没有任何基本事实。即使是人类写的解释也可能是不正确的,或者至少无法完全解释行为。此外,通常很难判断是否存在更好的解释。其次,我们无法控制神经元编码模式的复杂性或类型,也不能保证存在任何简单的解释。
为了解决这些缺点,我们创造了“神经元难题”:具有人类书面解释和精选证据的合成神经元。为了创建一个神经元难题,我们从一个人类写的解释开始,被认为是基本事实。接下来,我们收集文本摘录,并根据解释手动用“激活”(不对应于任何真实网络的激活,因为这些是合成神经元)标记它们的令牌。因此,每个谜题都是由一个解释和支持该解释的证据(即一组带有激活的文本摘录)形成的。
为了评估解释器,我们向解释器提供令牌和合成激活,并观察模型生成的解释是否与原始谜题解释匹配。我们可以改变谜题的难度,并编写新的谜题来测试我们感兴趣的某些模式。因此,这些谜题的集合构成了迭代我们的解释器技术的有用评估。我们总共创建了19个谜题,其中许多谜题的灵感来自我们和其他人发现的神经元,包括基于前面描述的“不是全部”神经元的谜题和GPT-2 Large中的“an”预测神经元。
[43]
Puzzle examples:
Prev

Next
对于每个谜题,我们确保证据足以让人类恢复原始解释。 31 然而,人们可以想象创造人类通常无法解决的谜题来评估超人的解释技术。我们的基线解释器方法可以解决 5 个难题中的 19 个。虽然它擅长在具有高激活率的代币中挑选出广泛的模式,但它始终无法在上下文中考虑代币或应用基础知识。解释者也不善于将负面证据纳入其解释中。例如,对于“不正确的历史年份”难题,解释者认识到神经元正在激活数字年份,但未能在提供的神经元未激活的文本摘录中纳入数字年份的证据。这些失败的案例激发了我们进行修订的实验。事实上,当我们将我们的复习技术应用于谜题时,我们又解决了 4 个谜题。
这些神经元谜题也提供了一个微弱的信号,即评分者是否是比我们目前发现的更复杂的神经元之间的有效区分器。我们通过编写一系列错误的解释为每个谜题创建了一个多项选择版本。例如,“这个神经元对美国或欧洲历史上的重要年份做出反应”是对“不正确的历史年份”难题的错误解释。其中一个错误的解释始终是具有高激活率的三个最常见令牌的基线。对于每个谜题,我们对该谜题的序列和激活的地面真相解释和所有错误解释进行评分,然后记录地面真相解释得分最高的次数。对于 16/19 谜题,地面真相解释排名最高,对于 18/19 的地面真相解释排名前两位。与解释者解决的 5/19 谜题相比,这个评估向我们表明,解释者目前比得分者更像是一个瓶颈。这可能反映了这样一个事实,即检测模式比验证给定解释的模式更困难。
然而,模拟器也存在系统错误。虽然它在模拟只需要查看孤立标记的模式(例如“与加拿大相关的单词”)方面表现良好,但它通常难以模拟涉及位置信息的模式以及涉及精确跟踪某些数量的模式。例如,在模拟“an”神经元时(“该神经元激活句子中可能后跟单词”an“的位置),结果包括非常高的误报。
我们正在发布代码来尝试我们构建的神经元难题。
讨论
限制和注意事项
我们的方法有许多局限性,我们希望可以在未来的工作中解决。
神经元可能无法解释
我们的工作假设神经元行为可以通过简短的自然语言解释来概括。由于多种原因,这种假设可能存在问题。
神经元可能代表许多特征
过去的研究表明,神经元可能没有特权作为计算单位。特别是,可能存在对应于多个语义概念的多语义神经元。虽然我们的解释技术可以而且经常确实会生成“X,有时是Y”的解释,但它不适合捕获多语义性的复杂实例。
分析顶级激活数据集示例在以前的工作中在实践中被证明是有用的,但也可能导致可解释性的错觉。通过关注顶级激活,我们的目的是将模型集中在神经元在极端激活值下行为的最重要方面,而不是在神经元行为可能不同的较低百分位数上。
减少或解决多语义性的一种我们没有探索的方法是将一些因子分解应用于神经元空间,例如NMF,SVD或字典学习。我们相信这可以与测向和训练可解释模型相辅相成。
外星人特征
此外,语言模型可能代表人类没有文字的外星概念。这可能是因为语言模型关心不同的事情,例如对下一个令牌预测任务有用的统计结构,或者因为模型已经发现了人类尚未发现的自然抽象,例如不同领域中的一些类似概念家族。
我们解释相关性,而不是机制
我们目前解释了网络输入与在固定分布上被解释的神经元之间的相关性。过去的工作表明,这可能并不反映两者之间的因果行为。
我们的解释也没有解释是什么导致了机械层面的行为,这可能导致我们的理解错误地概括。为了预测罕见或分布外的模型行为,我们似乎可能需要对模型有更多的机制理解。
模拟可能无法反映人类的理解
我们的评分方法依赖于模拟器模型,忠实地复制理想化的人对解释的反应。然而,在实践中,模拟器模型可能会接受人类不会接受的解释方面。在最坏的情况下,解释器模型和模拟器模型可能会隐式地执行某种隐写术及其解释。例如,如果解释器和模拟器模型将相同的虚假特征与实际特征混为一谈,则可能会发生这种情况(因此主体可能正在响应特征X,而解释者会错误地说Y,但模拟可能恰好在X上很高)。
理想情况下,可以通过训练模拟器模型来模仿人类模拟标签来缓解这种情况。我们计划在以后的工作中访问它。这还可以提高我们的仿真质量,并简化我们提示模型的方式。
有限的假设空间
为了更全面地理解变压器模型,我们需要从解释单个神经元转向解释电路。这意味着包括关于神经元下游效应的假设,关于注意力头和对数的假设,以及涉及多个输入和输出的假设。
Eventually, our explainer models would draw from a rich space of hypotheses, just like interpretability researchers do.
计算要求
我们的方法是相当计算密集型的。受试者模型中的激活次数(神经元、注意力头尺寸、残余尺寸)大致为哪里�n是主体模型参数的数量。如果我们使用恒定数量的前向传递来解释每个激活,那么在主题和解释器模型大小相同的情况下,整体计算规模为.
另一方面,与预训练本身相比,这可能是有利的。如果预训练使用参数近似线性缩放数据,则使用计算
.
上下文长度
另一个计算问题是上下文长度。我们当前的方法要求解释器模型的上下文长度至少是传递给主题模型的文本摘录的两倍。这意味着,如果解释器模型和主题模型具有相同的上下文长度,我们将只能在其完整上下文长度的最多一半内解释主题模型的行为,因此可能无法捕获仅在以后令牌中表现出来的某些行为。
标记化问题
标记化有几种方式会导致我们的方法出现问题:
1. 解释器和主题模型可以使用不同的标记化方案。激活数据集中的令牌来自主题模型的推理,并将使用该模型的标记化方案。当关联的字符串出现在发送到解释器模型的提示中时,它们可能会拆分为多个标记,或者它们可能是部分标记,不会自然出现在解释器模型的给定文本摘录中。
2. 我们使用字节对编码器,因此当将令牌一个接一个地提供给模型时,有时令牌无法合理地显示为字符。我们假设解码单个令牌是有意义的,但情况并非总是如此。原则上,当主题和解释器模型具有相同的编码时,我们本可以使用正确的标记,但我们在这项工作中忽略了这一点。
3. 我们在令牌及其相应的激活之间使用分隔符。理想情况下,解释器模型会将每个令牌、分隔符和激活视为单独的令牌。但是,我们不能保证它们不会合并,事实上,我们的制表符分隔符会与换行符合并,这可能会使助手的任务更加困难。
在某种程度上,这些标记化怪癖会影响模型对原始文本摘录中出现的标记的理解,它们可能会损害我们的解释和模拟的质量。
展望
虽然我们已经描述了当前版本方法的一些局限性,但我们相信我们的工作可以大大改进,并与其他现有方法有效集成。例如,对多语义性的成功研究可以立即使我们的方法产生更高的分数。相反,我们的方法可以帮助提高我们对叠加的理解,方法是尝试找到涵盖神经元在整个分布上的行为的多种解释,或者通过优化以在残差流中找到可解释的方向集(可能与字典学习等方法相结合)。我们还希望能够整合更广泛的常见可解释性技术,例如研究注意力头,使用消融进行验证等。纳入我们的自动化方法。
对思维链方法、工具使用和对话助手的改进也可用于改进解释。从长远来看,我们设想解释器模型可以生成、测试和迭代关于主题模型的丰富假设空间,类似于今天的可解释性研究人员。这将包括关于电路功能和分布外行为的假设。解释器模型的环境可能包括访问代码执行、主题模型可视化和与研究人员交谈等工具。这样的模型可以使用专家迭代或强化学习进行训练,模拟器/判断模型设置奖励。我们也可以通过辩论进行训练,其中两个相互竞争的助理模型都提出解释并批评对方的解释。
我们相信我们的方法可以开始有助于理解转换器语言模型内部正在发生的事情的高级图景。可以访问解释数据库的用户界面可以实现一种更加宏观的方法,可以帮助研究人员可视化数千或数百万个神经元,以查看它们之间的高级模式。我们也许很快就能在简单的应用程序上取得进展,比如检测奖励模型中的显著特征,或者理解微调模型与其基本模型之间的质变。
最终,我们希望能够使用自动可解释性来协助语言模型的审计,我们将尝试检测和理解模型何时未对齐。特别重要的是检测目标泛化或欺骗性对齐的示例,当模型在评估时行为一致,但在部署期间追求不同的目标时。这需要对每个内部行为都有非常透彻的了解。如果我们不知道助手本身是否值得信赖,那么使用强大的模型寻求帮助也可能很复杂。我们希望使用较小的可信模型作为帮助,要么扩展到完整的可解释性审计,要么将它们应用于可解释性将教会我们足够的模型如何工作,以帮助我们开发更强大的审计方法。
这项工作代表了OpenAI更广泛的对齐计划的具体实例,该计划使用强大的模型来帮助对齐研究人员。我们希望这是将可解释性扩展到全面理解未来更复杂和更有能力的模型的第一步。
内容
贡献
方法论:Nick 通过让 GPT-4 解释神经元的最初想法有效地启动了这个项目, 并展示一个简单的解释方法。威廉提出了最初的模拟和评分 方法和实施。Dan和Steven进行了许多实验,最终选择了提示和 说明/评分参数。
机器学习基础设施:威廉和尼克建立了代码库的初始版本。利奥和杰夫实施 用于执行可解释性的初始核心内部基础结构。史蒂文实施了顶级激活 管道。史蒂文和威廉开发了解释和评分的管道。许多其他杂项 贡献来自威廉,杰夫,丹和史蒂文。史蒂文创建了开源版本。
网络基础设施:尼克和威廉实现了神经元查看器,史蒂文的贡献较小, 丹和杰夫。Nick 实现了许多其他 UI 来探索各种神经元解释。史蒂文实施 人工数据收集 UI。
人类数据:史蒂文实施并分析了所有涉及承包商人类数据的实验:人类 解释基线和人体评分实验。尼克和威廉实施了早期研究人员的解释 基线。
替代令牌和基于权重的解释:Dan 实现了对代币权重和代币查找基线、下一个代币解释以及 神经元-神经元连接权重的基础设施和 UI。
修改:Henk实施并分析了主要的修订实验。尼克倡导并实施了 修订的初始概念证明。Leo实施了一项小规模的去风险实验。史蒂文帮助设计 最终修订管道。Leo和Dan对负面发现进行了许多重要的调查。
测:Leo有了这个想法,并实施了所有与测向相关的实验。
神经元谜题:Henk实现了所有的神经元难题和相关实验。威廉想出了 最初的想法。史蒂文和威廉对数据和策略提供了反馈。
主题、解释器和模拟器缩放:史蒂文实施并分析了助手大小, 模拟器大小和受试者大小实验。杰夫实施并分析了受试者训练时间实验。
消融评分:Jeff实施了消融基础设施和初始评分实验,Dan做出了贡献 许多有用的思考并进行了最后的实验。狮子座对理解和 消融效应的预测。
激活函数实验:杰夫实施了实验和分析。加布建议稀疏 激活函数,威廉提出了基于相关性的社区检测。
定性结果:在整个项目中,每个人都为定性发现做出了贡献。尼克和 威廉发现了许多最早的非平凡神经元。Dan通过比较发现了许多非平凡的神经元 标记基线,例如明喻神经元。史蒂文发现模式破坏神经元和其他上下文敏感 神经元。Leo发现了“不要停止”的神经元,并首先注意到解释过于宽泛。亨克有很多 关于解释和评分质量的定性发现。尼克发现了有趣的神经元-神经元连接和 有趣的神经元对在同一令牌上放电。威廉和杰夫研究了特定消融 神经元。
指导和指导:威廉和杰夫领导和管理了这个项目。简和杰夫 管理参与项目的团队成员。简、尼克、威廉和伊利亚的许多想法影响了 项目的方向。史蒂文指导了亨克。
确认
我们感谢Neel Nanda,Ryan Greenblatt,Paul Christiano,Chris Olah和Evan Hubinger关于以下方面的有益讨论 项目期间的指导。
我们感谢Ryan Greenblatt,Buck Shlegeris,Trenton Bricken,OpenAI对齐团队和Anthropic。 可解释性团队提供有用的讨论和反馈。
我们感谢 Cathy Yeh 对我们的代码进行了有用的检查并注意到了标记化问题。
我们感谢Carroll Wainwright和Chris Hesse在基础设施方面的帮助。
我们感谢为我们的人类数据实验编写和评估解释的承包商,以及 关于我们的说明的一些反馈。
我们感谢Rajan Troll为神经元谜题提供了人类基线。
我们感谢Thomas Degry的博客图形。
我们感谢其他OpenAI团队的支持,包括超级计算,研究加速和语言。 团队。
引文信息
请引用为:
Bills, et al., "Language models can explain neurons in language models", 2023.
BibTeX引用:
@misc{bills2023language,
title={Language models can explain neurons in language models},
author={
Bills, Steven and Cammarata, Nick and Mossing, Dan and Tillman, Henk and Gao, Leo and Goh, Gabriel and Sutskever, Ilya and Leike, Jan and Wu, Jeff and Saunders, William
},
year={2023},
howpublished = {\url{https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html}}
}
脚注
1. 主体和解释器可以是相同的模型,尽管对于我们的实验,我们通常使用较小的模型作为主题,使用我们最强的模型作为解释器。从长远来看,如果受试者是我们最强的模型,但我们不信任它作为助手,情况可能会逆转。[↩]
2. 因此,虽然应该训练解释器模型以尽可能使用 RL(使用模拟器模型作为训练信号)提供帮助,但模拟器应该被训练为模仿人类。如果模拟器模型通过做出人类不同意的预测来提高其性能,我们可能会冒着人类无法理解的解释的风险。[↩]
3. 但是,我们没有明确检查生成的文本摘录是否重叠。虽然原则上,解释“记住”行为的程度是合理的,因为它驱动了训练集上大部分主体模型的行为,但如果这是高分的主要驱动因素,那就不那么有趣了。根据对文本摘录的一些简单检查,这对至少99.8%的神经元来说不是问题。[↩]
4. 所有提示都以缩写格式显示,并且在使用结构化聊天完成 API 时会进行一些修改。有关完整详细信息,请参阅我们的代码库。[↩]
5. 虽然我们使用 GPT-4 作为大多数实验的模拟器模型,但公共 OpenAI API 不支持为较新的基于聊天的模型(如 GPT-4 和 GPT-3.5-turbo)返回 logprob。像原始 GPT-3.5 这样的旧型号支持对数。[↩]
6. 但效果在噪声范围内,研究人员主观上认为“一次一个”在相对较小的样本量上更好。[↩]
7. 请注意,这不是真实解释方差的无偏估计量,因为我们也使用样本作为分母。可以通过使用更大的样本来估计方差项来改进我们的方法。[↩]
8. 我们探索了更复杂的校准方法,但它们通常需要许多模拟,这些模拟[↩]
9. 从概念上讲,理想情况下,校准应该发生在一组不同的文本摘录上,这样我们就不会通过使用真实的平均值和方差来“作弊”。我们对不同样本量的作弊效果进行了实证研究,并认为在实践中它很小。[↩]
10.Matching standard deviations results in explained variance of 2�−1<�22ρ−1<ρ2. We also find empirically that it performs worse in ablation based scoring.[↩]
11.This might happen if subtle variations in the activation of a neuron (making the difference, say, between a correlation score of 0.9 and 1.0) played an outsized role in its function within the network.[↩]
12.Unlike GPT-2, GPT-4 is a model trained to follow instructions via RLHF.[↩]
[23]
13.请注意,由于 GPT-2 模型使用字节对编码器,因此有时我们的文本会有中间字符分隔符。有关更多讨论,请参阅此处,其[↩]
14.GPT-2 经过训练,有时会看到多个文档,由特殊的文本结尾标记分隔。在我们的工作中,我们确保所有 64 个代币都在同一个文档中。[↩]
15.对于其他激活功能,如GeGLU,这可能是不真实的,我们需要分别解释阳性和阴性激活。[↩]
16.从长远来看,我们希望走向一些争论,比如分数更像是一个极小值,而不是一个期望值。也就是说,我们想象一个模型得出一个解释,另一个模型给出反例。评分将考虑整个成绩单,从而衡量假设的稳健性[↩]
17.不幸的是,最初试图通过适度增加文本摘录的数量来做到这一点并没有被证明是有用的。[↩]
18.在大多数地方,我们使用平均值标准误差(SEM)的1.96倍或严格保守的统计数据来计算。如果需要,我们通过引导重新采样方法进行估计。[↩]
19.我们还尝试了线性预测,包括文本摘录中每个位置的位置嵌入加上标记嵌入;这种基于线性标记和位置的预测基线导致了非常小的定量改进,而没有质的变化。[↩]
20.如上所述,在非迭代设置中,我们发现解释者模型无法有效地在上下文中使用额外的文本摘录。[↩]
21.当我们中的一个人冷漠地看着这个神经元时,我们也得出了这个结论。只有在测试了诸如“所有学生必须在周一之前提交期末论文”之类的序列示例后,我们才意识到最初的解释过于宽泛。[↩]
22.我们的复习过程对它开始的解释也是不可知的,所以我们也可能从我们强大的单格基线开始,并根据相关句子进行复习。我们怀疑这将超过我们现有的结果,并计划在未来尝试类似的技术。[↩]
23.这种方法也可以应用于剩余流,因为它根本不假设特权基础。[↩]
24.我们在早期实验中发现,如果没有∑−1/2∑−1/2的重新参数化,高方差神经元将不成比例地支配所选的向量,导致样本多样性降低。使用∑−1/2∑−1/2的重新参数化确保初始化有利于较低的方差方向,并确保步长适当缩放。尽管进行了重新参数化,但我们仍然观察到了一定程度的坍塌。[↩]
25.我们还尝试根据系数的大小进行截断,这导致了更差的分数。[↩]然而,我们发现许多大型模型的第二层(第 1 层)的分数非常低,可能与它们包含许多死神经元的事实有关[↩]
17.每个参数倍增大约是 0.17 nats 的损失,因此 0.1 稀疏模型的参数效率大约降低了 8.5%,0.01 稀疏模型的参数效率大约降低了 40%。我们希望减少这种“可解释性税”能取得唾手可得的成果。[↩]
18.这些模型中的每一个都经过了总共 300B 个代币的训练。[↩]
19.对此的一个极具推测性的解释是,随着更多的训练,特征会变得更干净/更好(导致随机和最高分数增加),但由于叠加(导致仅随机分数降低),也有更多的干扰特征。 [↩]
20.,我们称之为“vibe”神经元[↩]
21.当我们把这些谜题交给一个不在项目中的研究人员时,他们解决了除了“an”预测谜题之外的所有谜题。事后看来,他们认为他们可以识别具有相似证据水平的未来下一个代币预测难题。[↩]
引用
1.
Interpretability
in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Wang, K., Variengien, A., Conmy, A., Shlegeris, B. and Steinhardt, J., 2022.
arXiv preprint arXiv:2211.00593.
2.
普遍性的玩具模型:逆向工程网络如何学习组操作
Chughtai,B.,Chan,L.和Nanda,N.,2023 年。arXiv预印本arXiv:2302.03025。
3.
自动化审计:一项雄心勃勃的具体技术研究提案 [链接]
Hubinger,E.,2021 年。
4.
CLIP-剖析:深度视觉网络中神经元表征的自动描述 Oikarinen,T.和Weng,T.,2022。
arXiv预印本arXiv:2204.10965。
5.
变压器重量矩阵的奇异值分解是高度可解释的 [链接]
Millidge,B. 和 Black,S.,2022 年。
6.
用自然语言
描述文本分布之间的差异 钟,R.,斯内尔,C.,克莱因,D.和斯坦哈特,J.,2022 年。机器学习国际会议,第 27099--27116 页。
7.
通过可解释的自动提示使用语言模型解释数据中的模式
辛格,C.,莫里斯,J.X.,阿内贾,J.,拉什,A.M.和高,J.,2022 年。arXiv预印本arXiv:2210.01848。
8.
GPT-4 技术报告
开放人工智能,2023 年。arXiv预印本arXiv:2303.08774。
9.
网络解剖:量化深度视觉表征的可解释性
Bau, D., Zhou, B., Khosla, A., Oliva, A. 和 Torralba, A., 2017.IEEE计算机视觉和模式识别会议论文集,第6541--6549页。
10.因果擦洗:一种严格测试可解释性假设的方法 [链接]
Chan, L., Garriga-Alonso, A., Goldowsky-Dill,
N., Greenblatt, R., Nitishinskaya, J.,
Radhakrishnan, A., Shlegeris, B. 和 Thomas, N., 2022.
11.深度视觉特征
的自然语言描述 埃尔南德斯,E.,施韦特曼,S.,鲍,D.,巴加什维利,T.,托拉尔巴,A.和安德烈亚斯,J.,2022 年。学习表征国际会议。
12.Softmax 线性单位
埃尔哈格, 休谟, T., 奥尔森, C., 南达, N., 亨尼汉, T., 约翰斯顿,
S., 埃尔肖克, S., 约瑟夫, N., 达斯萨尔玛, N., 曼恩, B., 埃尔南德斯,
D., 阿斯克尔, A., 恩杜斯, K., 琼斯, A., 排水, D., 陈, A.,
拜, Y., 甘古利, D., 洛维特, L., 哈特菲尔德-多兹, Z.,
克尼翁, J., 康纳利, T., 克拉维克, S., 福特, S., 卡达瓦斯,
S., 雅各布森, J., 特兰-约翰逊, E.,卡普兰,J.,克拉克,J.,布朗,T.,麦坎德利什,S.,阿莫德伊,D.和奥拉,C.,2022 年。变压器电路螺纹。
13.语言模型是无监督的多任务学习者
Radford,A.,Wu,J.,Child,R.,Luan,D.,Amodei,D.,Sutskever,I.等,2019。OpenAI 博客,第 1(8) 卷,第 9 页。
14.激活图谱
卡特,S.,阿姆斯特朗,Z.,舒伯特,L.,约翰逊,I.和奥拉,C.,2019。蒸馏,第 4(3)
卷,第 e15 页。
15.语言可解释性工具:NLP 模型的可扩展交互式可视化和分析 Tenney, I., Wexler, J., Bastings, J.,
Bolukbasi, T., Coenen, A., Gehrmann, S., Jiang, E., Pushkarna, M., Radebaugh, C., Reif, E. 等,2020 年。
arXiv预印本arXiv:2008.05122.
16.神经镜 [链接]
南达, N..
17.可视化深度网络的
高层特征 Erhan, D., Bengio, Y.,
Courville, A. 和 Vincent, P., 2009.蒙特利尔大学,第1341(3)卷,第1页。
18.通过深度可视化
理解神经网络 Yosinski, J., Clune, J., Nguyen, A., Fuchs, T. and
Lipson, H., 2015.arXiv预印本arXiv:1506.06579。
19.特征可视化Olah
,C.,Mordvintsev,A.和Schubert,L.,2017。提取。DOI: 10.23915/蒸馏.00007
20.高斯误差线性单位(gelus)
Hendrycks,D.和Gimpel,K.,2016。arXiv预印本arXiv:1606.08415。
21.解释神经NLP的因果中介分析:性别偏见
的案例Vig,J.,Gehrmann,S.,Belinkov,Y.,Qian,S.,Nevo,D.,Sakenis,S.,Huang,J.,Singer,Y.和Shieber,S.,2020。arXiv预印本arXiv:2004.12265.
22.定位和编辑 GPT
Meng, K.、Bau, D.、Andonian, A. 和 Belinkov, Y.(2022 年)中的事实关联。神经信息处理系统进展,第 35 卷,第 17359--17372 页。
23.训练语言模型以遵循人类反馈
的指令 欧阳,L.,吴,J.,姜,X.,阿尔梅达,D.,温赖特,C.,米什金,P.,张,C.,阿加瓦尔,S.,斯拉马,K.,雷,A.等,2022 年。神经信息处理系统进展,第 35 卷,第 27730--27744 页。
24.Glu变体改善变压器
沙泽尔,N.,2020 年。arXiv预印本arXiv:2002.05202。
25.放大:电路
简介 奥拉,C.,卡马拉塔,N.,舒伯特,L.,Goh,G.,彼得罗夫,M.和卡特,S.,2020 年。提取。DOI: 10.23915/蒸馏.00024.001
26.叠加
的玩具模型 埃尔哈格,N.,休谟,T.,奥尔森,C.,Schiefer,N.,Henighan,T.,Kravec,S.,哈特菲尔德-多兹,Z.,拉森比,R.,Drain,D.,陈,C.,格罗斯,R.,麦坎德利什,S.,卡普兰,J.,阿莫德伊,D.,瓦滕伯格,M.和奥拉,C.,2022 年。变压器电路螺纹。
27.通过辩论
AI安全Irving,G.,Christiano,P.和Amodei,D.,2018。arXiv预印本arXiv:1805.00899。
28.解读GPT:罗吉特镜头[链接]
怀旧主义者,2020年。
29.分析嵌入空间
中的变压器 Dar,G.,Geva,M.,Gupta,A.和Berant,J.,2022 年。arXiv预印本arXiv:2209.02535。
30.促使在大型语言模型中
引出推理的思维链 Wei, J., Wang, X.,
Schuurmans, D., Bosma, M., Chi, E., Le, Q. 和 Zhou, D., 2022.arXiv预印本arXiv:2201.11903。
31.辅助人类评估者的
自我批评模型 桑德斯,W.,叶,C.,吴,J.,比尔斯,S.,欧阳,L.,沃德,J.和莱克,J.,2022 年。arXiv预印本arXiv:2206.05802。
32.大海捞针寻找神经元:稀疏探测
案例研究 Gurnee,W.,Nanda,N.,Pauly,M.,Harvey,K.,Troitskii,D.和Bertsimas,D.,2023。arXiv预印本arXiv:2305.01610。
33.货币管理问题:英国货币经济学
论文的经验 古德哈特,C.,1975年。货币经济学,第1卷。
34.奖励模型过度优化
的缩放定律 Gao, L., Schulman, J. 和
Hilton, J., 2022.
35.引出潜在知识:如何判断你的眼睛是否欺骗了你[链接]
克里斯蒂安诺,P.,科特拉,A.和徐,M.,2021。
36.克里斯·奥拉对AGI安全的看法[链接]
Hubinger,E.,2019。
37.语言模型是少数镜头学习者
布朗,T.,曼恩,B.,莱德,N.,苏比亚,M.,卡普兰,法学博士,达里瓦尔,P.,尼拉坎坦,A.,希亚姆,P.,萨斯特里,G.,阿斯克尔,A.等,2020。神经信息处理系统进展,第 33 卷,第 1877--1901 页。
38.输入切换仿射网络:专为可解释性而设计的 rnn 架构 Foerster, J.N., Gilmer, J., Sohl-Dickstein, J.,
Chorowski, J. 和 Sussillo, D., 2017.
机器学习国际会议,第 1136--1145 页。
39.重新训练深度神经网络以促进布尔概念提取
Gonzalez, C., Loza Menc{\'\i}a, E. and Furnkranz, J., 2017.发现科学:第20届国际会议,DS
2017,日本京都,15年17月2017日至20日,论文集127,第143--<>页。
40.脊柱:稀疏可解释神经嵌入Subramanian
,A.,Pruthi,D.,Jhamtani,H.,Berg-Kirkpatrick,T.和Hovy,E.,2018。AAAI人工智能会议论文集,第32(1)卷。
41.使用非负稀疏嵌入学习有效且可解释的语义模型 Murphy, B., Talukdar, P. 和 Mitchell, T., 2012.
COLING 2012年论文集,第1933--1950页。
42.上下文学习和归纳负责人
奥尔森,C.,埃尔哈格,N.,南达,N.,约瑟夫,N.,达萨尔玛,N.,Henighan,T.,曼恩,B.,阿斯克尔,A.,白,Y.,陈,A.,康纳利,T.,Drain,D.,甘古利,D.,哈特菲尔德-多兹,Z.,埃尔南德斯,D.,约翰斯顿,S.,琼斯,A.,Kernion,J.,洛维特,L.,恩杜斯,K.,阿莫德伊,D.,布朗,T.,克拉克,J.,卡普兰,J.,麦坎德利什,S.和奥拉, C.,2022 年。变压器电路螺纹。
43.我们在 GPT-2 中发现了一个神经元 [链接]
米勒,J. 和 Neo,C.,2023 年。
44.神经网络
的有趣特性 Szegedy, C., Zaremba, W.,
Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I. and Fergus, R., 2013.arXiv预印本arXiv:1312.6199。
45.曲线检测器 卡马拉塔,N.,Goh,G.,
卡特,S.,舒伯特,L.,彼得罗夫,M.和奥拉,C.,2020 年。提取。DOI: 10.23915/蒸馏.00024.003
46.伯特
·博鲁克巴西、皮尔斯、袁、科宁、赖夫、维加斯和瓦滕伯格的可解释性错觉,2021 年。arXiv预印本arXiv:2104.07143。
47.可解释性
的基石Olah,C.,Satyanarayan,A.,Johnson,I.,Carter,S.,Schubert,L.,Ye,K.和Mordvintsev,A.,2018年。提取。DOI: 10.23915/蒸馏.00010
48.通过非负矩阵分解学习对象的部分
Lee, D.D. and Seung, H.S., 1999.自然》,第401卷(6755),第788--791页。英国伦敦自然出版集团。
49.使用混合超图正则化进行社区检测
的非负矩阵分解 Wu, W., Kwong, S., Zhou, Y., Jia, Y. and Gao, W., 2018.信息科学,第435卷,第263--281页。爱思唯尔。
50.Svcca:用于深度学习动力学和可解释性的奇异向量规范相关分析 Raghu,M.,Gilmer,J.,Yosinski,J.和Sohl-Dickstein,J.,2017。
神经信息处理系统进展,第30卷。
51.变压器重量矩阵的奇异值分解是高度可解释的 [链接]
Millidge,B. 和 Black,S.,2022 年。
52.使用稀疏自动编码器将特征从叠加中取出 [链接]
夏基,L.,布劳恩,D. 和米利奇,B.,2022 年。
53.关于可解释性和特征表征:对情感神经元
Donnelly,J.和Roegiest,A.的分析,2019。信息检索进展:第41届欧洲IR研究会议,ECIR 2019,德国科隆,14年18月2019日至41日,论文集,第一部分795,第802--<>页。
54.Cyclegan,隐写
大师Chu,C.,Zhmoginov,A.和Sandler,M.,2017年。arXiv预印本arXiv:1712.02950。
55.N2G:一种用于量化大型语言模型中可解释神经元表示的可扩展方法 Foote, A.,
Nanda, N., Kran, E., Konstas, I. and
Barez, F..
ICLR 2023 可信和可靠的大规模机器学习模型研讨会。
56.训练计算最优大型语言模型
霍夫曼,J.,博尔乔德,S.,Mensch,A.,布恰茨卡娅,E.,蔡,T.,卢瑟福,E.,卡萨斯,D.D.L.,亨德里克斯,洛杉矶,韦尔布尔,J.,克拉克,A.等,2022 年。arXiv预印本arXiv:2203.15556。
57.目标误概化:为什么正确的规格不足以实现正确的目标
Shah, R., Varma, V., Kumar, R., Phuong, M.,
Krakovna, V., Uesato, J. 和 Kenton, Z., 2022.
58.深度学习角度
的对齐问题 Ngo, R., Chan, L. and Mindermann, S., 2023.
59.高级机器学习系统中
学习优化的风险 Hubinger, E., Merwijk, C.V.,
Mikulik, V., Skalse, J. 和 Garrabrant, S.,
2021.
60.我们的对齐研究方法 [链接]
Leike, J., Schulman, J. 和 Wu, J., 2022.
相关文章
近期评论
-
来自: GPT-4V(ision)系统卡

-
来自: GPT-4V(ision)系统卡
-
来自: OpenAI研究 用对抗样本攻击机器学习