OpenAI研究 引入激活图集
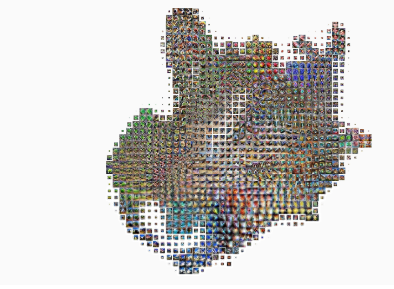
我们创建了 激活图集 ( 与谷歌研究人员合作 ),这是一种可视化神经元之间的相互作用可以表示的新技术。随着人工智能系统部署在越来越敏感的环境中,更好地了解其内部决策过程将使我们能够识别弱点并调查故障。
现代神经网络 经常被 批评 为“黑匣子”。尽管他们在各种问题上都取得了成功,但我们对他们如何在内部做出决策的了解有限。激活图谱是一种查看盒子内部发生的一些事情的新方法。

激活图集建立在特征可视化的基础上,这是一种研究神经网络隐藏层可以表示什么的技术。 特征可视化的早期 工作 主要集中在 单个神经元上。通过收集数十万个神经元相互作用的例子并将它们可视化,激活图集从单个神经元移动到可视化这些神经元共同代表的空间。

了解神经网络内部发生的事情不仅仅是一个科学好奇心的问题——我们缺乏理解会阻碍我们审计神经网络的能力,并在高风险的情况下确保它们是安全的。通常情况下,如果要部署一个关键软件,可以审查代码的所有路径,甚至可以进行形式验证,但是使用神经网络,我们进行这种审查的能力目前受到了很大限制。借助激活图集,人类可以发现神经网络中未预料到的问题——例如,网络依赖虚假相关性对图像进行分类的地方,或者在两个类别之间重复使用某个特征会导致奇怪的错误。人类甚至可以利用这种理解来“攻击”模型,修改图像来愚弄它。
例如,可以创建一种特殊的激活图谱来显示网络如何区分煎锅和炒锅。我们看到的许多事物都是人们所期望的。煎锅更方形,而炒锅更圆更深。但该模型似乎还了解到,煎锅和炒锅也可以通过周围的食物来区分——特别是,炒锅是由面条支撑的。将面条添加到图像的一角将有 45% 的时间骗过模型!这类似于 对抗性补丁的工作,但基于人类的理解。

其他基于网络超载某些特征检测器的人为设计的攻击通常更有效(有些成功率高达 93%)。但是面条的例子特别有趣,因为它是模型选择相关但不是因果关系的事物并给出正确答案的例子。这与我们可能特别担心的错误类型具有结构相似性,例如公平和偏见问题。
激活图集的效果比我们预期的要好,并且似乎强烈表明神经网络激活对人类有意义。这让我们更加乐观地认为,在强烈意义上实现视觉模型的可解释性是可能的。
我们很高兴能与谷歌的研究人员合作完成这项工作 。我们相信,随着 AI 研究的进展,共同开展与安全相关的研究有助于我们所有人确保为社会带来最佳成果。
相关文章
近期评论
-
来自: GPT-4V(ision)系统卡

-
来自: GPT-4V(ision)系统卡
-
来自: OpenAI研究 用对抗样本攻击机器学习