
OpenAI研究 学习合作、竞争和沟通
开发了一种新算法 MADDPG,用于多代理环境中的集中学习和分散执行,允许代理学习协作和相互竞争。
MADDPG 从actor-critic 强化学习技术中汲取灵感, 扩展了一种名为DDPG的强化学习算法 ;其他小组正在 探索这些想法的变体 和 并行实施 。
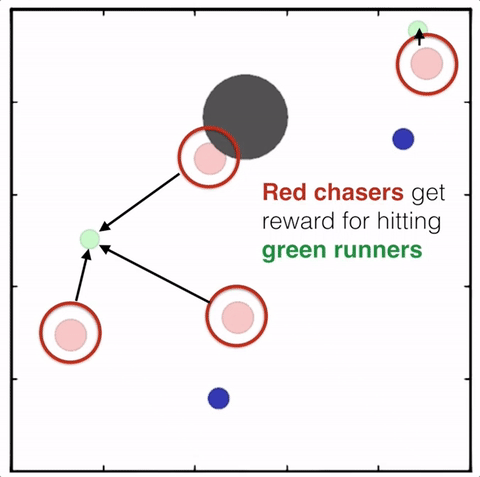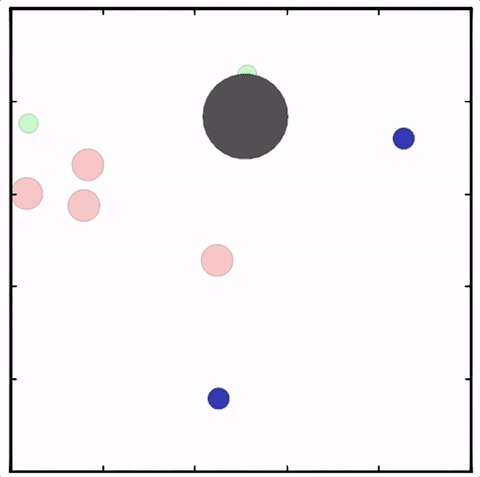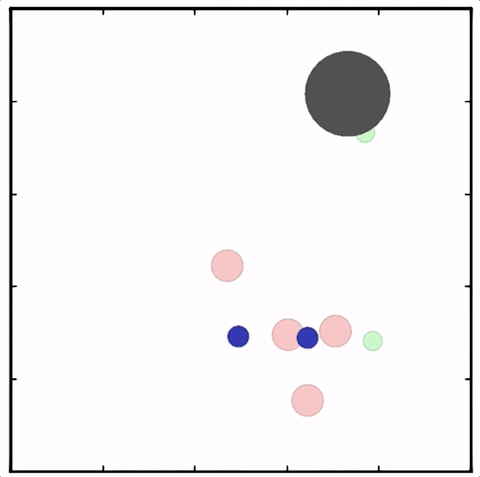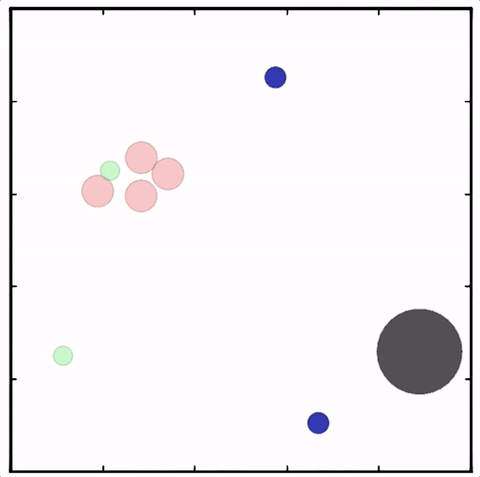
我们将模拟中的每个代理人视为“演员”,每个演员都从“评论家”那里获得建议,帮助演员决定在训练期间要加强哪些动作。传统上,critic 试图预测 特定状态下动作的价值(即我们期望在未来获得的奖励),代理(参与者 )使用该值来更新其策略。这比直接使用奖励更稳定,奖励可能会有很大差异。为了使训练多个能够以全局协调的方式行动的代理成为可能,我们增强了我们的批评家,以便他们可以访问所有代理的观察和行动,如下图所示。
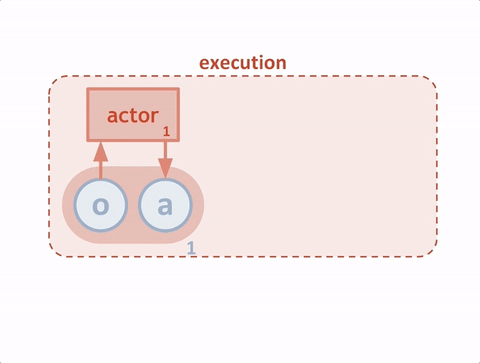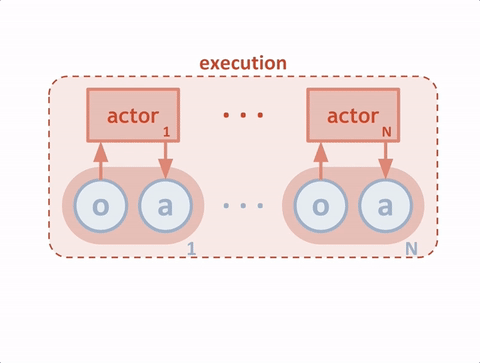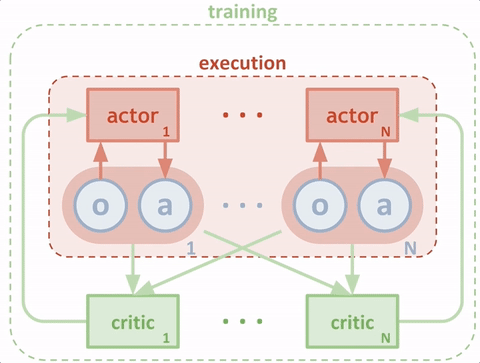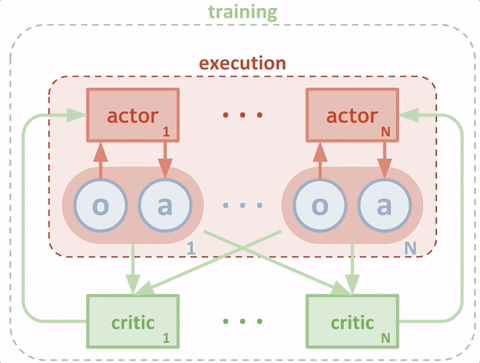
我们的代理人不需要在测试时访问中央评论家;他们根据自己的观察并结合对其他代理人行为的预测来采取行动。由于中央评论家是为每个代理人独立学习的,我们的方法也可用于模拟代理人之间的任意奖励结构,包括奖励相反的对抗案例。
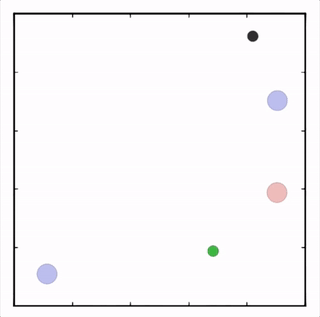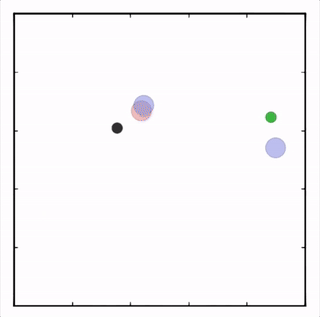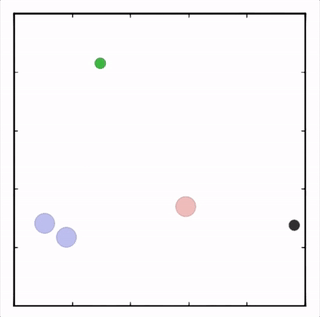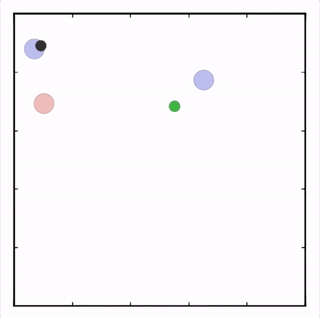
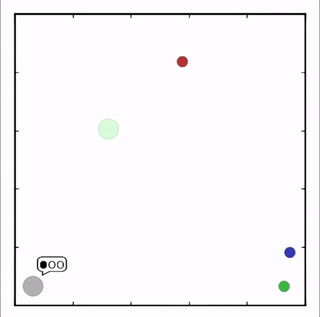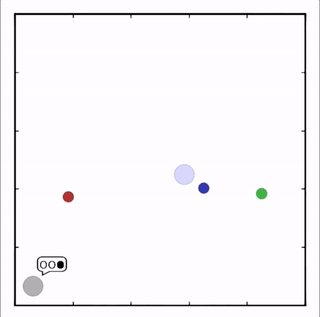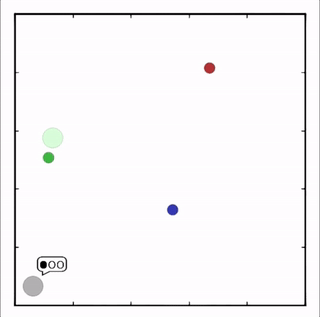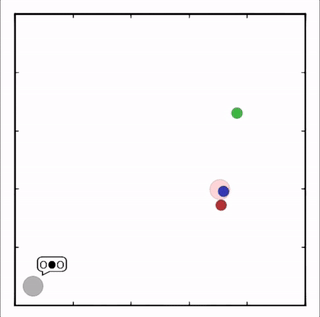
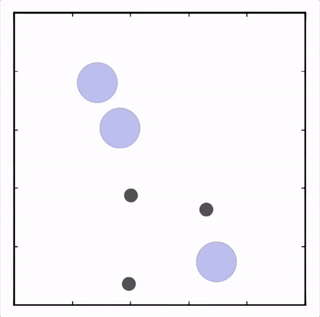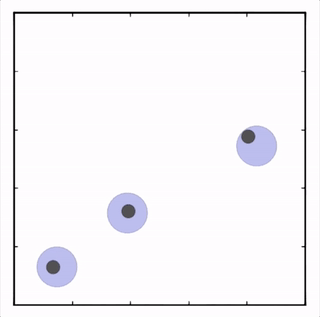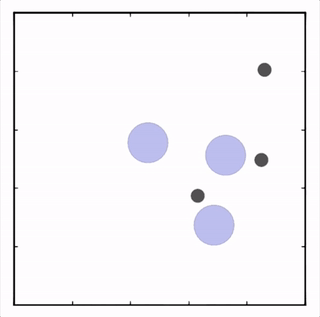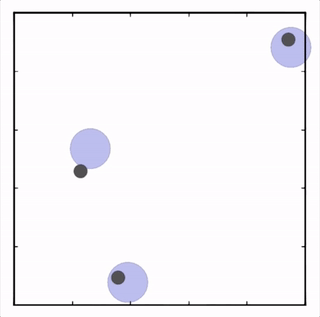
我们在各种任务上测试了我们的方法,它在所有任务上的表现都优于 DDPG。在上面的动画中,您可以看到,从左到右:两个 AI 智能体试图前往特定位置并学习分开以向对方智能体隐藏他们的预定位置;一个代理人将地标的名称传达 给另一个代理人;和三个特工协调前往地标而不会相互碰撞。
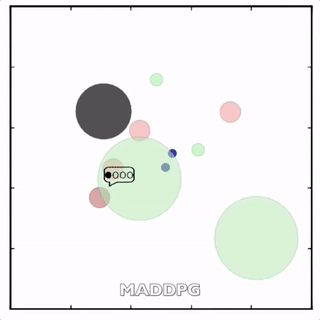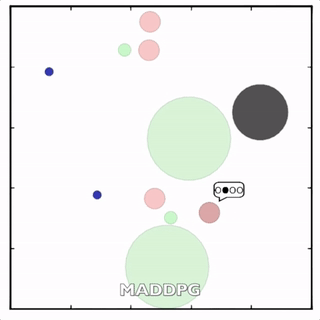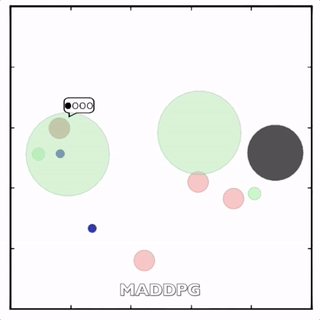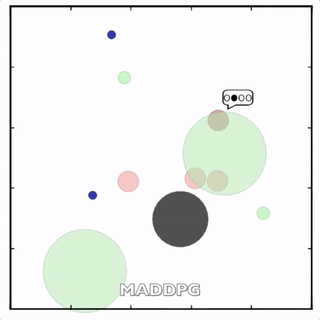
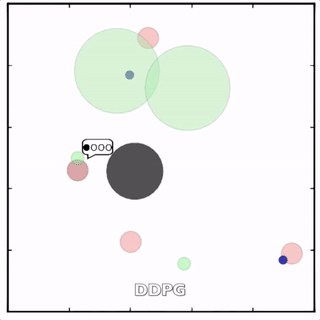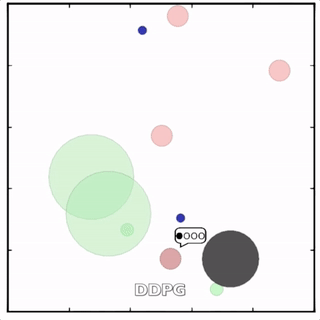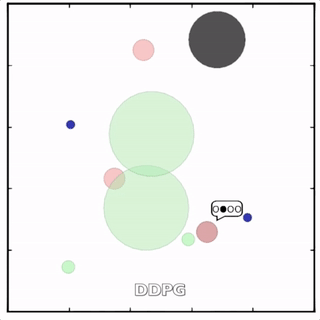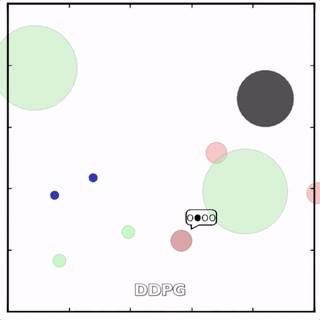
传统 RL 挣扎的地方
传统的分散式 RL 方法——DDPG、演员评论学习、深度 Q 学习等——难以在多智能体环境中学习,因为在每个时间步,每个智能体都将尝试学习预测其他智能体的行为,同时也采取自己的行动。在竞争情况下尤其如此。MADDPG 雇佣了一个中央评论家来为代理人提供关于他们同行的观察和潜在行动的信息,将不可预测的环境转变为可预测的环境。
使用策略梯度方法带来了进一步的挑战:因为这些方法表现出高方差,所以当奖励不一致时,很难学习正确的策略。我们还发现,加入批评家,在提高稳定性的同时,仍然未能解决我们的几个环境,例如合作交流。似乎在训练过程中考虑其他人的行为对于学习协作策略很重要。
初步研究
在我们开发 MADDPG 之前,在使用去中心化技术时,我们注意到如果说话者发送关于去哪里的不一致消息,听众代理通常会学会忽略说话者。然后代理会将与说话者消息相关的所有权重设置为 0,从而有效地震耳欲聋。一旦发生这种情况,训练就很难恢复,因为没有任何反馈,说话者永远不知道自己说的是否正确。为了解决这个问题,我们研究了 最近的分层强化项目中概述的一种技术,这让我们可以迫使听众将说话者的话语纳入其决策过程。这个修复没有用,因为虽然它迫使听众注意说话者,但它并不能帮助说话者弄清楚要说什么是相关的。我们的集中式评论方法通过帮助说话者了解哪些话语可能与其他代理人的行为相关来帮助应对这些挑战。有关我们的更多结果,您可以观看以下视频:

下一步
代理建模在人工智能研究中有着 丰富的历史,并且之前已经研究过其中的许多场景。许多 先前的研究都 考虑了只有少量时间步长和小状态空间的游戏。深度学习让我们能够处理复杂的视觉输入,强化学习为我们提供了长期学习行为的工具。现在我们可以使用这些功能同时训练多个智能体,而无需他们了解环境的动态(环境在每个时间步长如何变化),我们可以在学习的同时解决更广泛的涉及交流和语言的问题来自环境的高维信息。
相关文章
近期评论
-
来自: GPT-4V(ision)系统卡

-
来自: GPT-4V(ision)系统卡
-
来自: OpenAI研究 用对抗样本攻击机器学习