
OpenAI研究 从人类偏好中学习
构建安全 AI 系统的一个步骤是消除人类编写目标函数的需要,因为对复杂目标使用简单代理,或者将复杂目标弄错一点,可能会导致不良甚至危险的行为。通过与 DeepMind 的安全团队合作,我们开发了一种算法,可以通过告知两种提议的行为中哪一种更好来推断人类的需求。
我们提出了一种学习算法,该算法使用少量人类反馈来解决现代 RL 环境。之前已经 探索过具有 人类反馈的机器学习系统 ,但我们已经扩大了该方法的规模,使其能够处理更复杂的任务。我们的算法需要来自人类评估者的 900 位反馈来学习后空翻——这是一项看似简单的任务,但判断起来很简单,但具体 说明却很困难。

整个训练过程是人类、智能体对目标的理解和 RL 训练之间的 3 步反馈循环。
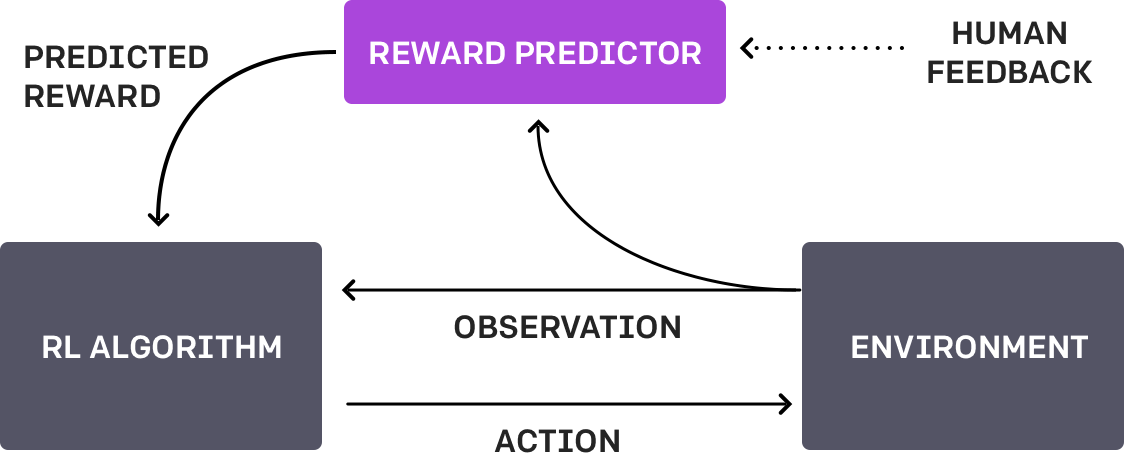
我们的 AI 代理首先在环境中随机行动。定期将其行为的两个视频片段提供给人类,人类决定两个片段中的哪一个最接近实现其目标——在本例中为后空翻。人工智能通过找到最能解释人类判断的奖励函数,逐步建立任务目标模型。然后它使用 RL 来学习如何实现该目标。随着其行为的改进,它会继续就最不确定哪个更好的轨迹对寻求人类反馈,并进一步完善其对目标的理解。
我们的方法展示了有前途的样本效率——如前所述,后空翻视频需要不到 1000 位的人类反馈。它花费了人类评估者不到一个小时的时间,而在后台,政策积累了大约 70 小时的整体经验(模拟速度比实时速度快得多)。我们将继续努力减少反馈量人类需要供给。您可以在以下视频中看到训练过程的加速版本。

我们已经在模拟机器人和 Atari 领域的许多任务上测试了我们的方法(没有获得奖励函数的访问权限:所以在 Atari 中,没有访问游戏分数)。我们的智能体可以从人类反馈中学习,以在我们测试的许多环境中实现强大的,有时甚至是超人的表现。在下面的动画中,您可以看到使用我们的技术训练的智能体玩各种 Atari 游戏。每个框架右侧的水平条代表每个代理人对人类评估员对其当前行为的认可程度的预测。这些可视化表明,经过人类反馈训练的代理人在 Seaquest(左)中学习评估氧气的价值,在 Breakout 和 Pong(中)中预测奖励,或者在 Enduro(右)中学习如何从崩溃中恢复。
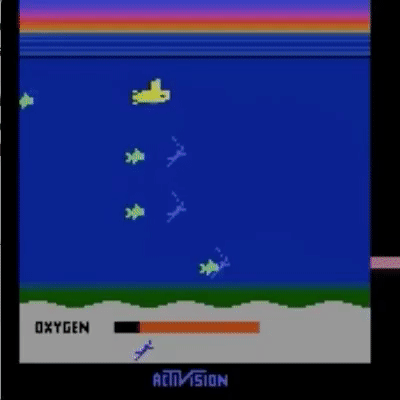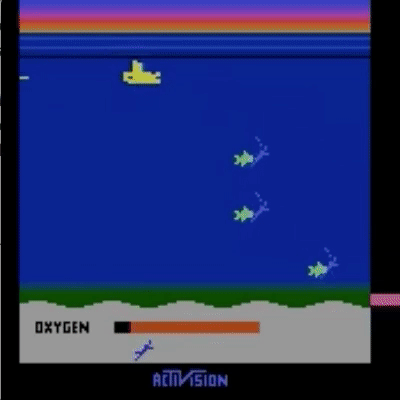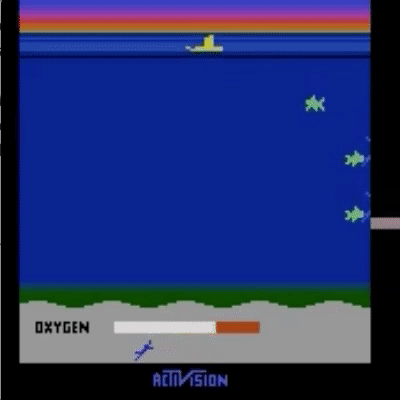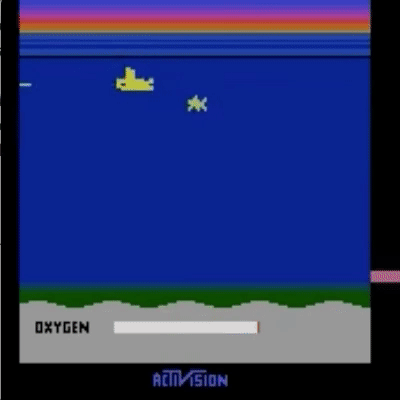


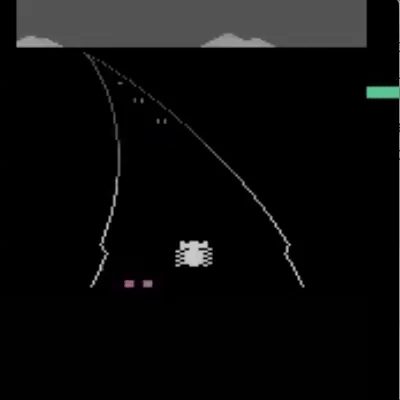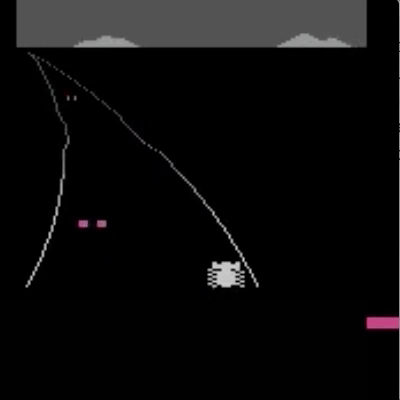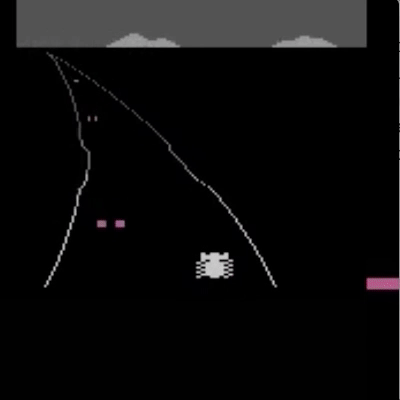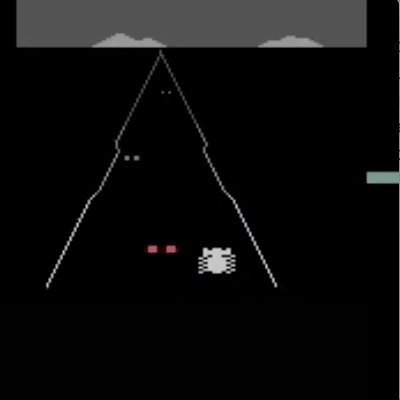
请注意,反馈不需要与环境的正常奖励函数保持一致:例如,我们可以训练我们的代理在 Enduro 中精确地与其他汽车保持平衡,而不是通过超过它们来最大化游戏分数。有时我们还发现,从反馈中学习比使用正常奖励函数的强化学习效果更好,因为人类比编写环境奖励的人更好地塑造奖励。
挑战
我们算法的性能仅与人类评估者关于哪些行为看起来正确的直觉一样好 ,因此如果人类没有很好地掌握任务,他们可能不会提供那么多有用的反馈。相关地,在某些领域,我们的系统可能会导致代理采用欺骗评估者的策略。例如,一个本应抓取物品的机器人将其操纵器置于相机和物体之间,使其 看起来只是 在抓取物体,如下所示。

我们通过添加视觉提示(上面动画中的粗白线)来解决这个特殊问题,使人类评估者更容易估计深度。
这篇文章中描述的研究是与 DeepMind 的 Jan Leike、Miljan Martic 和 Shane Legg 合作完成的。我们的两个组织计划继续就涉及长期 AI 安全的主题进行合作。我们认为像这样的技术是朝着能够学习以人为中心的目标的安全人工智能系统迈出的一步,并且可以补充和扩展现有的方法,如强化和模仿学习。这篇文章代表了 OpenAI 安全团队所做的工作;如果您有兴趣解决此类问题,请 加入我们!
脚注


相比之下,我们花了两个小时编写自己的奖励函数(右上角的动画)来让机器人后空翻,虽然它成功了,但它比仅通过人类反馈(左上角)训练的那个要优雅得多。我们认为,在许多情况下,人类反馈可以让我们比手动制定目标更直观、更快速地指定特定目标。
您可以使用 Hopper 的以下奖励函数在健身房中复制此后空翻 :
def reward_fn(a, ob):
backroll = -ob[7]
height = ob[0]
vel_act = a[0] * ob[8] + a[1] * ob[9] + a[2] * ob[10]
backslide = -ob[5]
return backroll * (1.0 + .3 * height + .1 * vel_act + .05 * backslide)相关文章
近期评论
-
来自: GPT-4V(ision)系统卡

-
来自: GPT-4V(ision)系统卡
-
来自: OpenAI研究 用对抗样本攻击机器学习